 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMU-XLSR: Semantically-Aligned Multimodal Utterance-level Cross-Lingual Speech Representation
Paper and Code
May 17, 2022

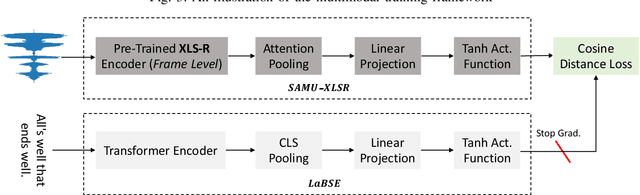

We propose the SAMU-XLSR: Semantically-Aligned Multimodal Utterance-level Cross-Lingual Speech Representation learning framework. Unlike previous works on speech representation learning, which learns multilingual contextual speech embedding at the resolution of an acoustic frame (10-20ms), this work focuses on learning multimodal (speech-text) multilingual speech embedding at the resolution of a sentence (5-10s) such that the embedding vector space is semantically aligned across different languages. We combine state-of-the-art multilingual acoustic frame-level speech representation learning model XLS-R with the Language Agnostic BERT Sentence Embedding (LaBSE) model to create an utterance-level multimodal multilingual speech encoder SAMU-XLSR. Although we train SAMU-XLSR with only multilingual transcribed speech data, cross-lingual speech-text and speech-speech associations emerge in its learned representation space. To substantiate our claims, we use SAMU-XLSR speech encoder in combination with a pre-trained LaBSE text sentence encoder for cross-lingual speech-to-text translation retrieval, and SAMU-XLSR alone for cross-lingual speech-to-speech translation retrieval. We highlight these applications by performing several cross-lingual text and speech translation retrieval tasks across several datasets.