 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARCO: Phoneme-Augmented Robust Contextual ASR via Contrastive Entity Disambiguation
Sep 04, 2025Automatic speech recognition (ASR) systems struggle with domain-specific named entities, especially homophones. Contextual ASR improves recognition but often fails to capture fine-grained phoneme variations due to limited entity diversity. Moreover, prior methods treat entities as independent tokens, leading to incomplete multi-token biasing. To address these issues, we propose Phoneme-Augmented Robust Contextual ASR via COntrastive entity disambiguation (PARCO), which integrates phoneme-aware encoding, contrastive entity disambiguation, entity-level supervision, and hierarchical entity filtering. These components enhance phonetic discrimination, ensure complete entity retrieval, and reduce false positives under uncertainty. Experiments show that PARCO achieves CER of 4.22% on Chinese AISHELL-1 and WER of 11.14% on English DATA2 under 1,000 distractors, significantly outperforming baselines. PARCO also demonstrates robust gains on out-of-domain datasets like THCHS-30 and LibriSpeech.
Mamba-based Decoder-Only Approach with Bidirectional Speech Modeling for Speech Recognition
Nov 11, 2024


Selective state space models (SSMs) represented by Mamba have demonstrated their computational efficiency and promising outcomes in various tasks, including automatic speech recognition (ASR). Mamba has been applied to ASR task with the attention-based encoder-decoder framework, where the cross-attention mechanism between encoder and decoder remains. This paper explores the capability of Mamba as the decoder-only architecture in ASR task. Our MAmba-based DEcoder-ONly approach (MADEON) consists of a single decoder that takes speech tokens as a condition and predicts text tokens in an autoregressive manner. To enhance MADEON, we further propose speech prefixing that performs bidirectional processing on speech tokens, which enriches the contextual information in the hidden states. Our experiments show that MADEON significantly outperforms a non-selective SSM. The combination of speech prefixing and the recently proposed Mamba-2 yields comparable performance to Transformer-based models on large datasets.
An Attribute Interpolation Method in Speech Synthesis by Model Merging
Jun 30, 2024With the development of speech synthesis, recent research has focused on challenging tasks, such as speaker generation and emotion intensity control. Attribute interpolation is a common approach to these tasks. However, most previous methods for attribute interpolation require specific modules or training methods. We propose an attribute interpolation method in speech synthesis by model merging. Model merging is a method that creates new parameters by only averaging the parameters of base models. The merged model can generate an output with an intermediate feature of the base models. This method is easily applicable without specific modules or training methods, as it uses only existing trained base models. We merged two text-to-speech models to achieve attribute interpolation and evaluated its performance on speaker generation and emotion intensity control tasks. As a result, our proposed method achieved smooth attribute interpolation while keeping the linguistic content in both tasks.
Exploring the Capability of Mamba in Speech Applications
Jun 24, 2024This paper explores the capability of Mamba, a recently proposed architecture based on state space models (SSMs), as a competitive alternative to Transformer-based models. In the speech domain, well-designed Transformer-based models, such as the Conformer and E-Branchformer, have become the de facto standards. Extensive evaluations have demonstrated the effectiveness of these Transformer-based models across a wide range of speech tasks. In contrast, the evaluation of SSMs has been limited to a few tasks, such as automatic speech recognition (ASR) and speech synthesis. In this paper, we compared Mamba with state-of-the-art Transformer variants for various speech applications, including ASR, text-to-speech, spoken language understanding, and speech summarization. Experimental evaluations revealed that Mamba achieves comparable or better performance than Transformer-based models, and demonstrated its efficiency in long-form speech processing.
Structured State Space Decoder for Speech Recognition and Synthesis
Oct 31, 2022Automatic speech recognition (ASR) systems developed in recent years have shown promising results with self-attention models (e.g., Transformer and Conformer), which are replacing conventional recurrent neural networks. Meanwhile, a structured state space model (S4) has been recently proposed, producing promising results for various long-sequence modeling tasks, including raw speech classification. The S4 model can be trained in parallel, same as the Transformer model. In this study, we applied S4 as a decoder for ASR and text-to-speech (TTS) tasks by comparing it with the Transformer decoder. For the ASR task, our experimental results demonstrate that the proposed model achieves a competitive word error rate (WER) of 1.88%/4.25% on LibriSpeech test-clean/test-other set and a character error rate (CER) of 3.80%/2.63%/2.98% on the CSJ eval1/eval2/eval3 set. Furthermore, the proposed model is more robust than the standard Transformer model, particularly for long-form speech on both the datasets. For the TTS task, the proposed method outperforms the Transformer baseline.
Acoustic Event Detection with Classifier Chains
Feb 17, 2022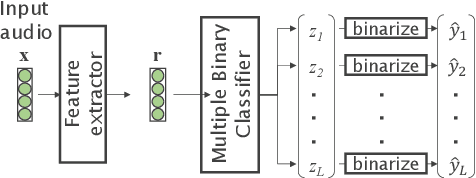

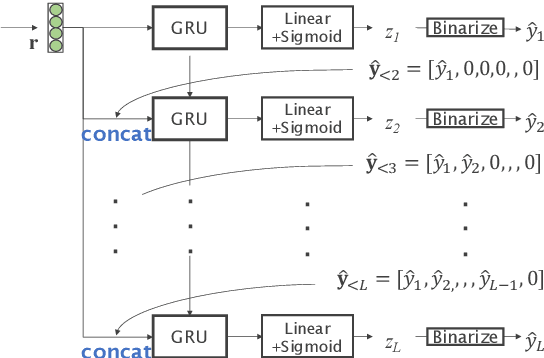
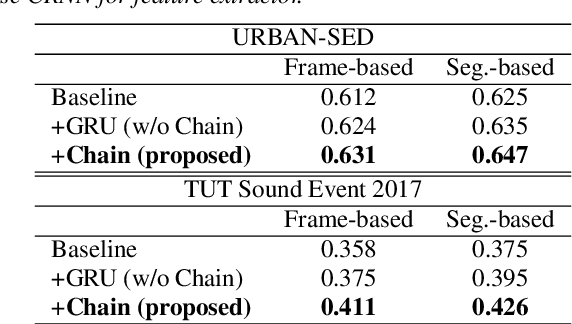
This paper proposes acoustic event detection (AED) with classifier chains, a new classifier based on the probabilistic chain rule. The proposed AED with classifier chains consists of a gated recurrent unit and performs iterative binary detection of each event one by one. In each iteration, the event's activity is estimated and used to condition the next output based on the probabilistic chain rule to form classifier chains. Therefore, the proposed method can handle the interdependence among events upon classification, while the conventional AED methods with multiple binary classifiers with a linear layer and sigmoid function have placed an assumption of conditional independence. In the experiments with a real-recording dataset, the proposed method demonstrates its superior AED performance to a relative 14.80% improvement compared to a convolutional recurrent neural network baseline system with the multiple binary classifiers.