 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple yet Effective Gradient-Free Graph Convolutional Networks
Paper and Code
Feb 01, 2023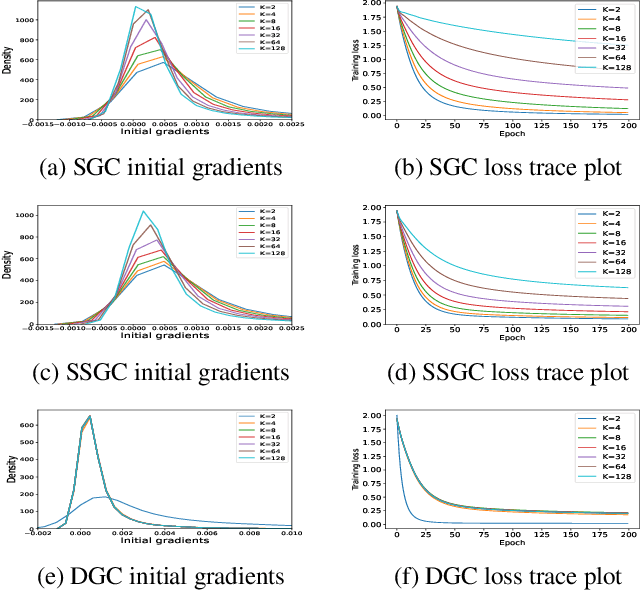
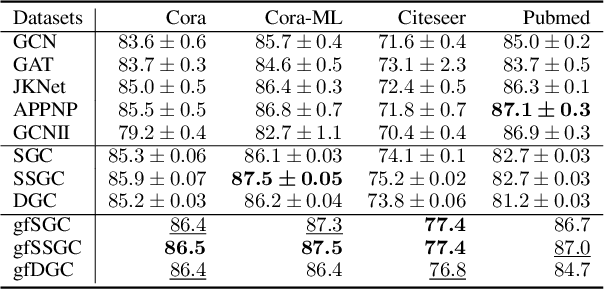
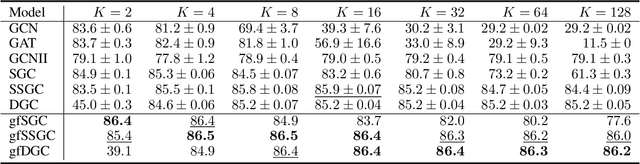
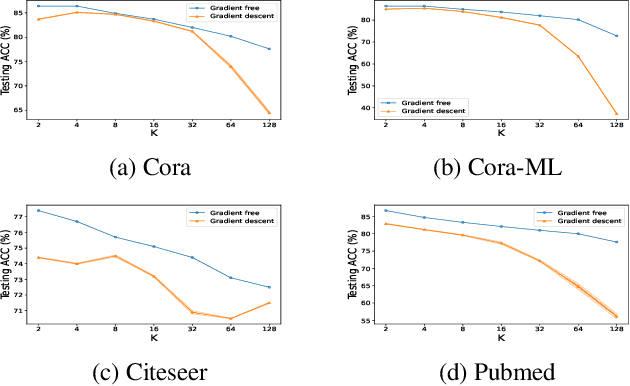
Linearized Graph Neural Networks (GNNs) have attracted great attention in recent years for graph representation learning. Compared with nonlinear Graph Neural Network (GNN) models, linearized GNNs are much more time-efficient and can achieve comparable performances on typical downstream tasks such as node classification. Although some linearized GNN variants are purposely crafted to mitigate ``over-smoothing", empirical studies demonstrate that they still somehow suffer from this issue. In this paper, we instead relate over-smoothing with the vanishing gradient phenomenon and craft a gradient-free training framework to achieve more efficient and effective linearized GNNs which can significantly overcome over-smoothing and enhance the generalization of the model. The experimental results demonstrate that our methods achieve better and more stable performances on node classification tasks with varying depths and cost much less training time.