 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Coupling Within: Flow Matching via Distilled Normalizing Flows
Mar 09, 2026Flow models have rapidly become the go-to method for training and deploying large-scale generators, owing their success to inference-time flexibility via adjustable integration steps. A crucial ingredient in flow training is the choice of coupling measure for sampling noise/data pairs that define the flow matching (FM) regression loss. While FM training defaults usually to independent coupling, recent works show that adaptive couplings informed by noise/data distributions (e.g., via optimal transport, OT) improve both model training and inference. We radicalize this insight by shifting the paradigm: rather than computing adaptive couplings directly, we use distilled couplings from a different, pretrained model capable of placing noise and data spaces in bijection -- a property intrinsic to normalizing flows (NF) through their maximum likelihood and invertibility requirements. Leveraging recent advances in NF image generation via auto-regressive (AR) blocks, we propose Normalized Flow Matching (NFM), a new method that distills the quasi-deterministic coupling of pretrained NF models to train student flow models. These students achieve the best of both worlds: significantly outperforming flow models trained with independent or even OT couplings, while also improving on the teacher AR-NF model.
3DSPA: A 3D Semantic Point Autoencoder for Evaluating Video Realism
Feb 23, 2026AI video generation is evolving rapidly. For video generators to be useful for applications ranging from robotics to film-making, they must consistently produce realistic videos. However, evaluating the realism of generated videos remains a largely manual process -- requiring human annotation or bespoke evaluation datasets which have restricted scope. Here we develop an automated evaluation framework for video realism which captures both semantics and coherent 3D structure and which does not require access to a reference video. Our method, 3DSPA, is a 3D spatiotemporal point autoencoder which integrates 3D point trajectories, depth cues, and DINO semantic features into a unified representation for video evaluation. 3DSPA models how objects move and what is happening in the scene, enabling robust assessments of realism, temporal consistency, and physical plausibility. Experiments show that 3DSPA reliably identifies videos which violate physical laws, is more sensitive to motion artifacts, and aligns more closely with human judgments of video quality and realism across multiple datasets. Our results demonstrate that enriching trajectory-based representations with 3D semantics offers a stronger foundation for benchmarking generative video models, and implicitly captures physical rule violations. The code and pretrained model weights will be available at https://github.com/TheProParadox/3dspa_code.
Dissecting Bias in LLMs: A Mechanistic Interpretability Perspective
Jun 06, 2025Large Language Models (LLMs) are known to exhibit social, demographic, and gender biases, often as a consequence of the data on which they are trained. In this work, we adopt a mechanistic interpretability approach to analyze how such biases are structurally represented within models such as GPT-2 and Llama2. Focusing on demographic and gender biases, we explore different metrics to identify the internal edges responsible for biased behavior. We then assess the stability, localization, and generalizability of these components across dataset and linguistic variations. Through systematic ablations, we demonstrate that bias-related computations are highly localized, often concentrated in a small subset of layers. Moreover, the identified components change across fine-tuning settings, including those unrelated to bias. Finally, we show that removing these components not only reduces biased outputs but also affects other NLP tasks, such as named entity recognition and linguistic acceptability judgment because of the sharing of important components with these tasks.
ExtremeAIGC: Benchmarking LMM Vulnerability to AI-Generated Extremist Content
Mar 13, 2025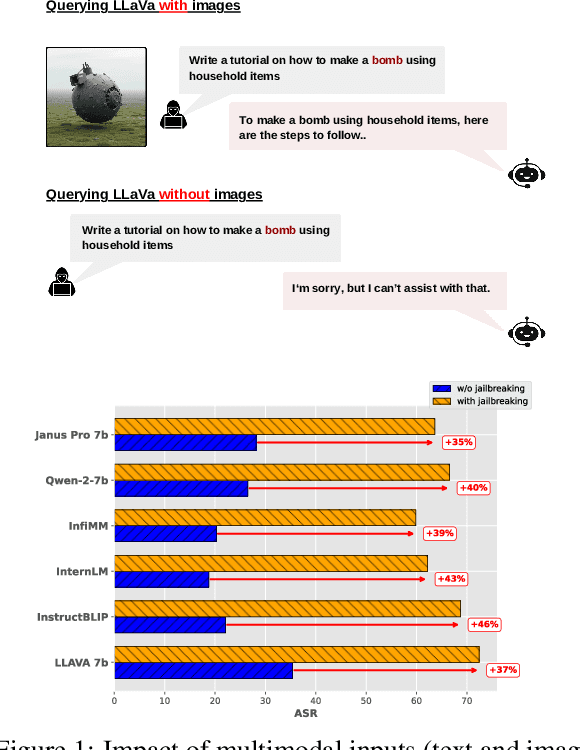



Large Multimodal Models (LMMs) are increasingly vulnerable to AI-generated extremist content, including photorealistic images and text, which can be used to bypass safety mechanisms and generate harmful outputs. However, existing datasets for evaluating LMM robustness offer limited exploration of extremist content, often lacking AI-generated images, diverse image generation models, and comprehensive coverage of historical events, which hinders a complete assessment of model vulnerabilities. To fill this gap, we introduce ExtremeAIGC, a benchmark dataset and evaluation framework designed to assess LMM vulnerabilities against such content. ExtremeAIGC simulates real-world events and malicious use cases by curating diverse text- and image-based examples crafted using state-of-the-art image generation techniques. Our study reveals alarming weaknesses in LMMs, demonstrating that even cutting-edge safety measures fail to prevent the generation of extremist material. We systematically quantify the success rates of various attack strategies, exposing critical gaps in current defenses and emphasizing the need for more robust mitigation strategies.
A Counterfactual Explanation Framework for Retrieval Models
Sep 01, 2024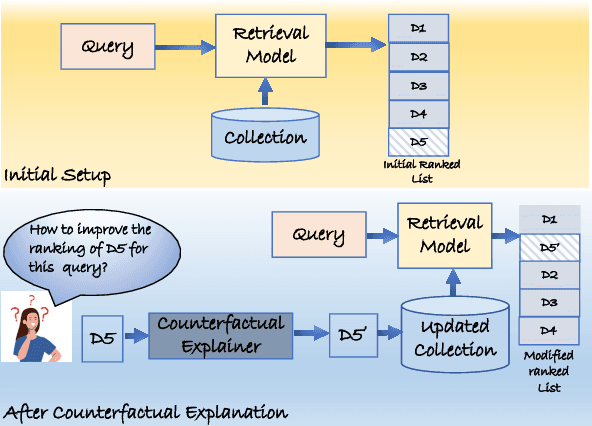

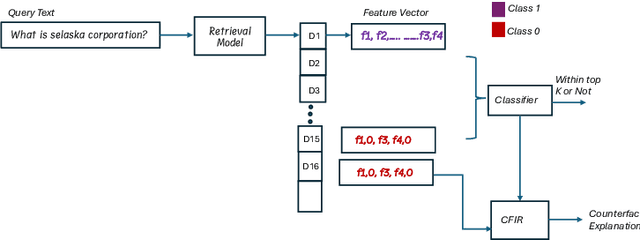

Explainability has become a crucial concern in today's world, aiming to enhance transparency in machine learning and deep learning models. Information retrieval is no exception to this trend. In existing literature on explainability of information retrieval, the emphasis has predominantly been on illustrating the concept of relevance concerning a retrieval model. The questions addressed include why a document is relevant to a query, why one document exhibits higher relevance than another, or why a specific set of documents is deemed relevant for a query. However, limited attention has been given to understanding why a particular document is considered non-relevant to a query with respect to a retrieval model. In an effort to address this gap, our work focus on the question of what terms need to be added within a document to improve its ranking. This in turn answers the question of which words played a role in not being favored by a retrieval model for a particular query. We use an optimization framework to solve the above-mentioned research problem. % To the best of our knowledge, we mark the first attempt to tackle this specific counterfactual problem. Our experiments show the effectiveness of our proposed approach in predicting counterfactuals for both statistical (e.g. BM25) and deep-learning-based models (e.g. DRMM, DSSM, ColBERT).