 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Few-shot Learning for Fair Classification
Paper and Code
Oct 05, 2021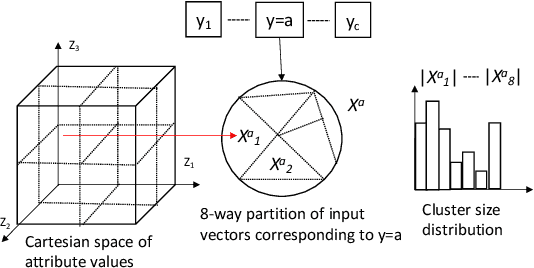
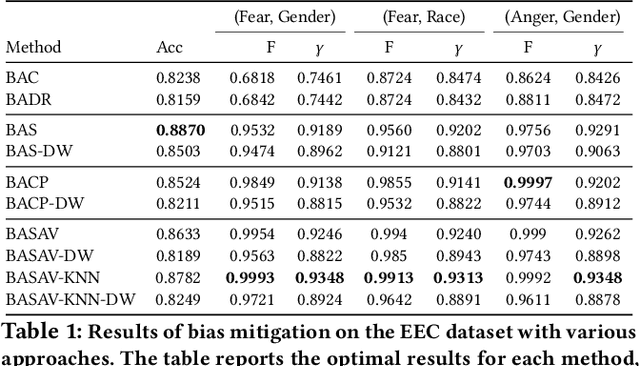
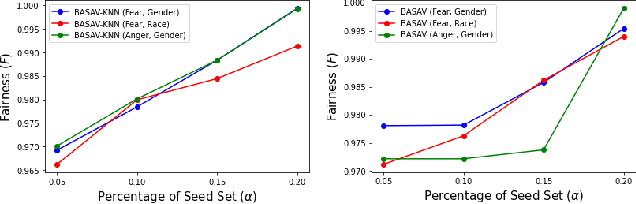
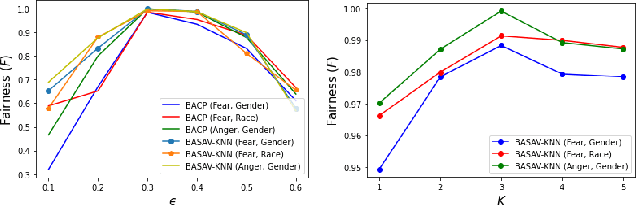
In this paper, we propose a general framework for mitigating the disparities of the predicted classes with respect to secondary attributes within the data (e.g., race, gender etc.). Our proposed method involves learning a multi-objective function that in addition to learning the primary objective of predicting the primary class labels from the data, also employs a clustering-based heuristic to minimize the disparities of the class label distribution with respect to the cluster memberships, with the assumption that each cluster should ideally map to a distinct combination of attribute values. Experiments demonstrate effective mitigation of cognitive biases on a benchmark dataset without the use of annotations of secondary attribute values (the zero-shot case) or with the use of a small number of attribute value annotations (the few-shot case).