Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen are Iterative Gaussian Processes Reliably Accurate?
Paper and Code

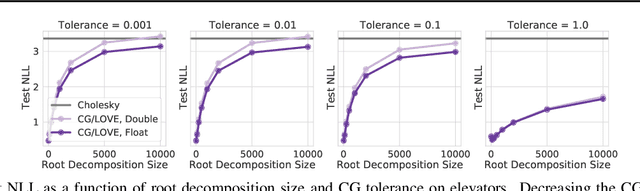

While recent work on conjugate gradient methods and Lanczos decompositions have achieved scalable Gaussian process inference with highly accurate point predictions, in several implementations these iterative methods appear to struggle with numerical instabilities in learning kernel hyperparameters, and poor test likelihoods. By investigating CG tolerance, preconditioner rank, and Lanczos decomposition rank, we provide a particularly simple prescription to correct these issues: we recommend that one should use a small CG tolerance ($\epsilon \leq 0.01$) and a large root decomposition size ($r \geq 5000$). Moreover, we show that L-BFGS-B is a compelling optimizer for Iterative GPs, achieving convergence with fewer gradient updates.
* ICML 2021 OPTML Workshop
View paper on