 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical-Knowledge Driven Multiple Instance Learning for Classifying Severe Abdominal Anomalies on Prenatal Ultrasound
Jul 02, 2025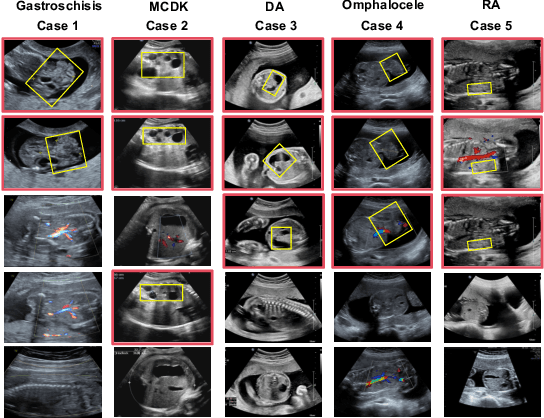
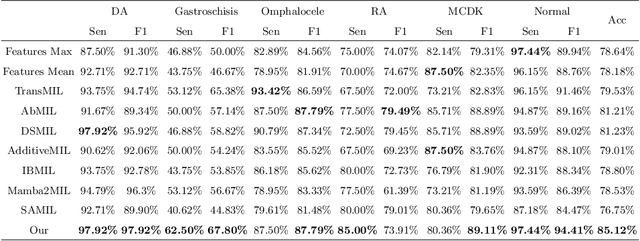
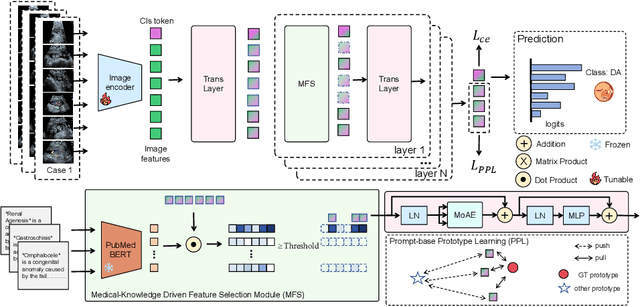

Fetal abdominal malformations are serious congenital anomalies that require accurate diagnosis to guide pregnancy management and reduce mortality. Although AI has demonstrated significant potential in medical diagnosis, its application to prenatal abdominal anomalies remains limited. Most existing studies focus on image-level classification and rely on standard plane localization, placing less emphasis on case-level diagnosis. In this paper, we develop a case-level multiple instance learning (MIL)-based method, free of standard plane localization, for classifying fetal abdominal anomalies in prenatal ultrasound. Our contribution is three-fold. First, we adopt a mixture-of-attention-experts module (MoAE) to weight different attention heads for various planes. Secondly, we propose a medical-knowledge-driven feature selection module (MFS) to align image features with medical knowledge, performing self-supervised image token selection at the case-level. Finally, we propose a prompt-based prototype learning (PPL) to enhance the MFS. Extensively validated on a large prenatal abdominal ultrasound dataset containing 2,419 cases, with a total of 24,748 images and 6 categories, our proposed method outperforms the state-of-the-art competitors. Codes are available at:https://github.com/LL-AC/AAcls.
DiffVein: A Unified Diffusion Network for Finger Vein Segmentation and Authentication
Feb 03, 2024Finger vein authentication, recognized for its high security and specificity, has become a focal point in biometric research. Traditional methods predominantly concentrate on vein feature extraction for discriminative modeling, with a limited exploration of generative approaches. Suffering from verification failure, existing methods often fail to obtain authentic vein patterns by segmentation. To fill this gap, we introduce DiffVein, a unified diffusion model-based framework which simultaneously addresses vein segmentation and authentication tasks. DiffVein is composed of two dedicated branches: one for segmentation and the other for denoising. For better feature interaction between these two branches, we introduce two specialized modules to improve their collective performance. The first, a mask condition module, incorporates the semantic information of vein patterns from the segmentation branch into the denoising process. Additionally, we also propose a Semantic Difference Transformer (SD-Former), which employs Fourier-space self-attention and cross-attention modules to extract category embedding before feeding it to the segmentation task. In this way, our framework allows for a dynamic interplay between diffusion and segmentation embeddings, thus vein segmentation and authentication tasks can inform and enhance each other in the joint training. To further optimize our model, we introduce a Fourier-space Structural Similarity (FourierSIM) loss function, which is tailored to improve the denoising network's learning efficacy. Extensive experiments on the USM and THU-MVFV3V datasets substantiates DiffVein's superior performance, setting new benchmarks in both vein segmentation and authentication tasks.
Materials Expert-Artificial Intelligence for Materials Discovery
Dec 05, 2023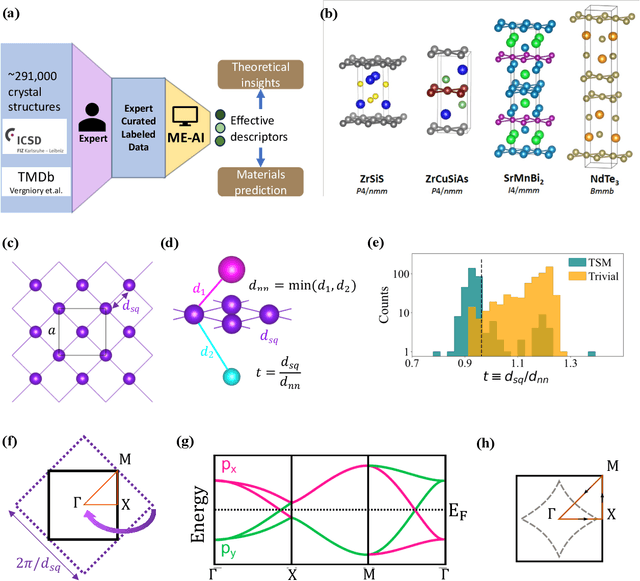


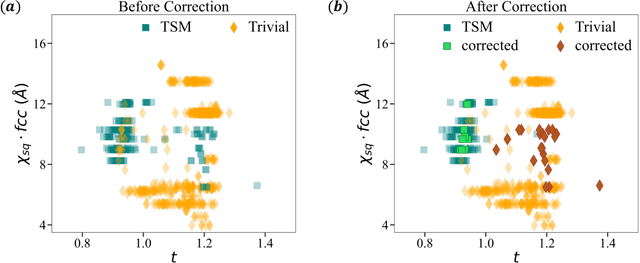
The advent of material databases provides an unprecedented opportunity to uncover predictive descriptors for emergent material properties from vast data space. However, common reliance on high-throughput ab initio data necessarily inherits limitations of such data: mismatch with experiments. On the other hand, experimental decisions are often guided by an expert's intuition honed from experiences that are rarely articulated. We propose using machine learning to "bottle" such operational intuition into quantifiable descriptors using expertly curated measurement-based data. We introduce "Materials Expert-Artificial Intelligence" (ME-AI) to encapsulate and articulate this human intuition. As a first step towards such a program, we focus on the topological semimetal (TSM) among square-net materials as the property inspired by the expert-identified descriptor based on structural information: the tolerance factor. We start by curating a dataset encompassing 12 primary features of 879 square-net materials, using experimental data whenever possible. We then use Dirichlet-based Gaussian process regression using a specialized kernel to reveal composite descriptors for square-net topological semimetals. The ME-AI learned descriptors independently reproduce expert intuition and expand upon it. Specifically, new descriptors point to hypervalency as a critical chemical feature predicting TSM within square-net compounds. Our success with a carefully defined problem points to the "machine bottling human insight" approach as promising for machine learning-aided material discovery.
Explicit3D: Graph Network with Spatial Inference \\for Single Image 3D Object Detection
Feb 13, 2023



Indoor 3D object detection is an essential task in single image scene understanding, impacting spatial cognition fundamentally in visual reasoning. Existing works on 3D object detection from a single image either pursue this goal through independent predictions of each object or implicitly reason over all possible objects, failing to harness relational geometric information between objects. To address this problem, we propose a dynamic sparse graph pipeline named Explicit3D based on object geometry and semantics features. Taking the efficiency into consideration, we further define a relatedness score and design a novel dynamic pruning algorithm followed by a cluster sampling method for sparse scene graph generation and updating. Furthermore, our Explicit3D introduces homogeneous matrices and defines new relative loss and corner loss to model the spatial difference between target pairs explicitly. Instead of using ground-truth labels as direct supervision, our relative and corner loss are derived from the homogeneous transformation, which renders the model to learn the geometric consistency between objects. The experimental results on the SUN RGB-D dataset demonstrate that our Explicit3D achieves better performance balance than the-state-of-the-art.