 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Word Discovery with Segmental Neural Language Models
Paper and Code
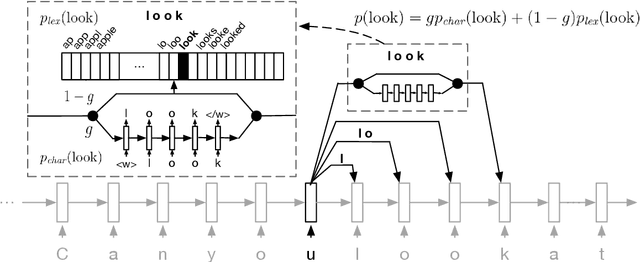
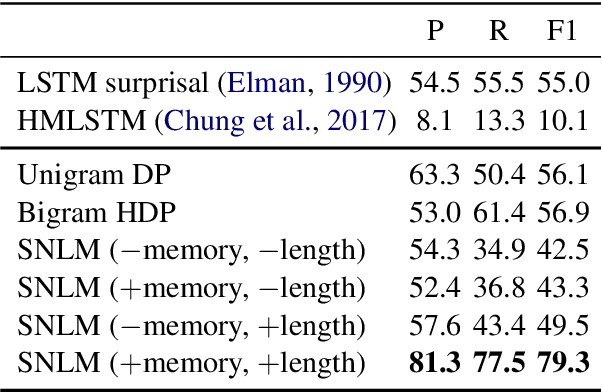
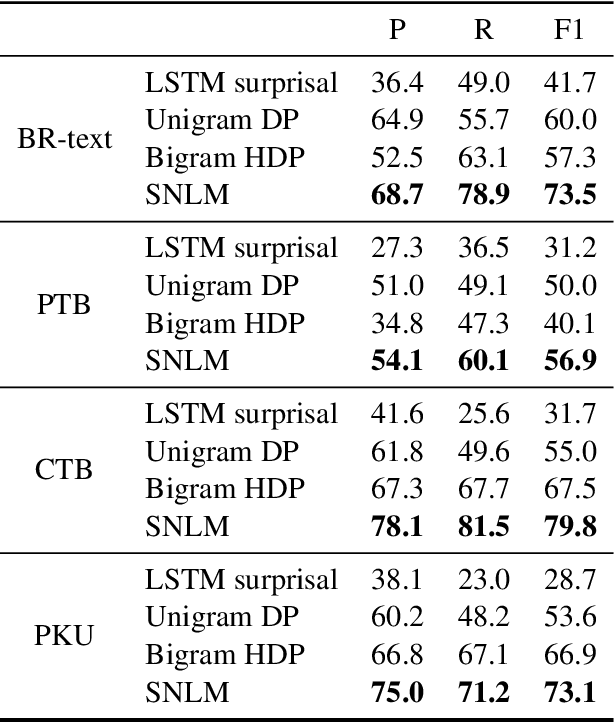
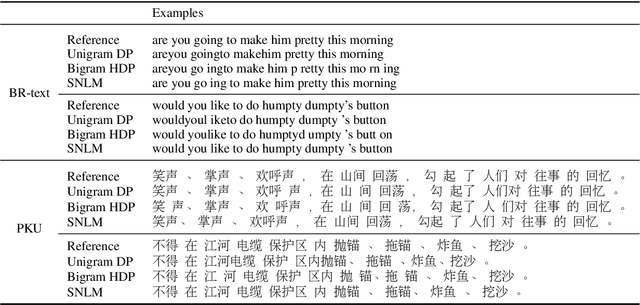
We propose a segmental neural language model that combines the representational power of neural networks and the structure learning mechanism of Bayesian nonparametrics, and show that it learns to discover semantically meaningful units (e.g., morphemes and words) from unsegmented character sequences. The model generates text as a sequence of segments, where each segment is generated either character-by-character from a sequence model or as a single draw from a lexical memory that stores multi-character units. Its parameters are fit to maximize the marginal likelihood of the training data, summing over all segmentations of the input, and its hyperparameters are likewise set to optimize held-out marginal likelihood. To prevent the model from overusing the lexical memory, which leads to poor generalization and bad segmentation, we introduce a differentiable regularizer that penalizes based on the expected length of each segment. To our knowledge, this is the first demonstration of neural networks that have predictive distributions better than LSTM language models and also infer a segmentation into word-like units that are competitive with the best existing word discovery models.