Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Interrogative Utterances with Recurrent Neural Networks
Paper and Code
Nov 16, 2015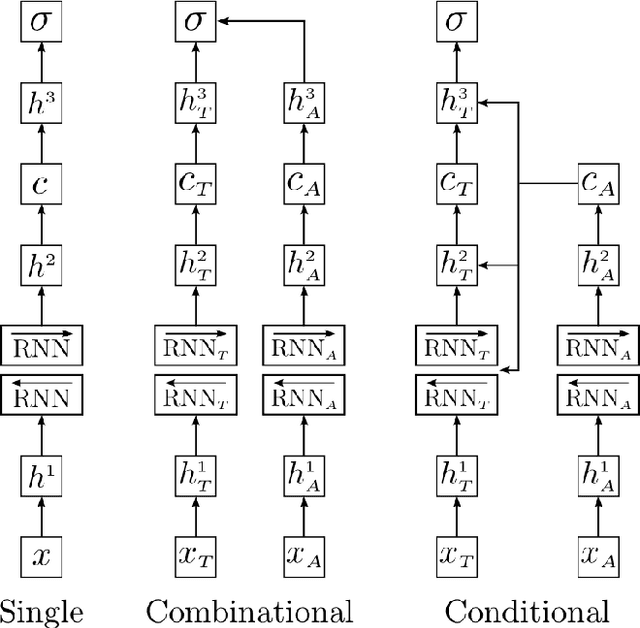
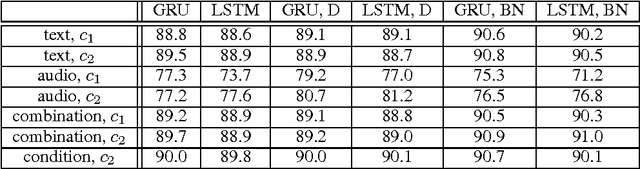
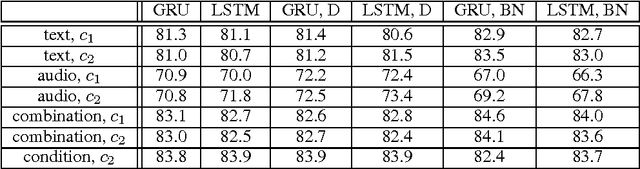

In this paper, we explore different neural network architectures that can predict if a speaker of a given utterance is asking a question or making a statement. We com- pare the outcomes of regularization methods that are popularly used to train deep neural networks and study how different context functions can affect the classification performance. We also compare the efficacy of gated activation functions that are favorably used in recurrent neural networks and study how to combine multimodal inputs. We evaluate our models on two multimodal datasets: MSR-Skype and CALLHOME.
* 6 pages, accepted to NIPS 2015 Workshop on Machine Learning for
Spoken Language Understanding and Interaction
View paper on