 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised learning of the brain connectivity dynamic using residual D-net
Apr 20, 2018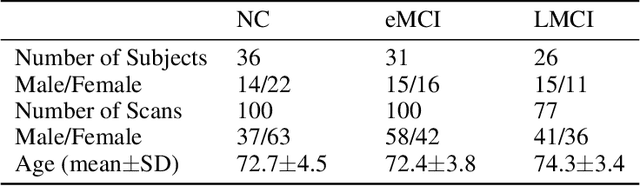
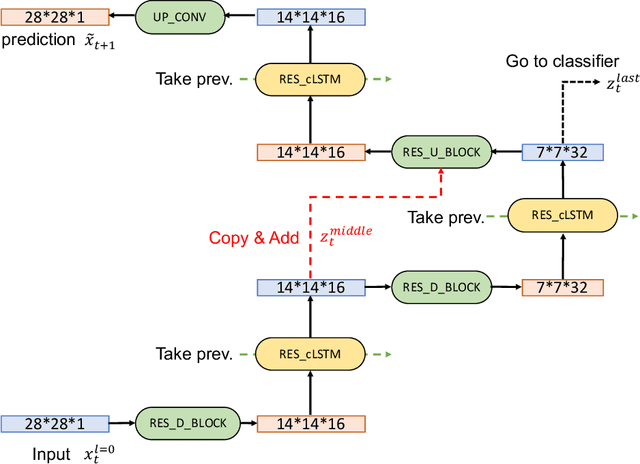
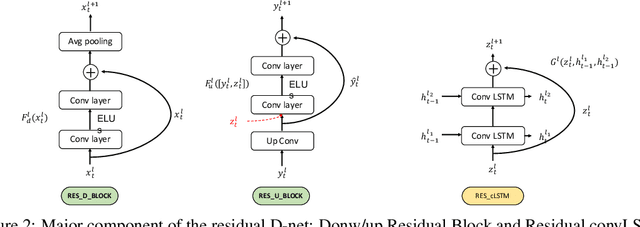
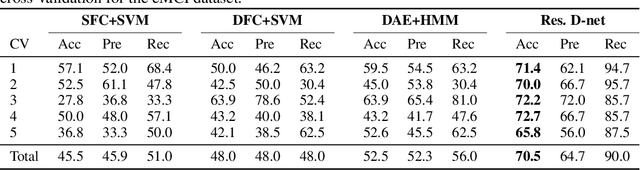
In this paper, we propose a novel unsupervised learning method to learn the brain dynamics using a deep learning architecture named residual D-net. As it is often the case in medical research, in contrast to typical deep learning tasks, the size of the resting-state functional Magnetic Resonance Image (rs-fMRI) datasets for training is limited. Thus, the available data should be very efficiently used to learn the complex patterns underneath the brain connectivity dynamics. To address this issue, we use residual connections to alleviate the training complexity through recurrent multi-scale representation. We conduct two classification tasks to differentiate early and late stage Mild Cognitive Impairment (MCI) from Normal healthy Control (NC) subjects. The experiments verify that our proposed residual D-net indeed learns the brain connectivity dynamics, leading to significantly higher classification accuracy compared to previously published techniques.
Structured Sequence Modeling with Graph Convolutional Recurrent Networks
Dec 22, 2016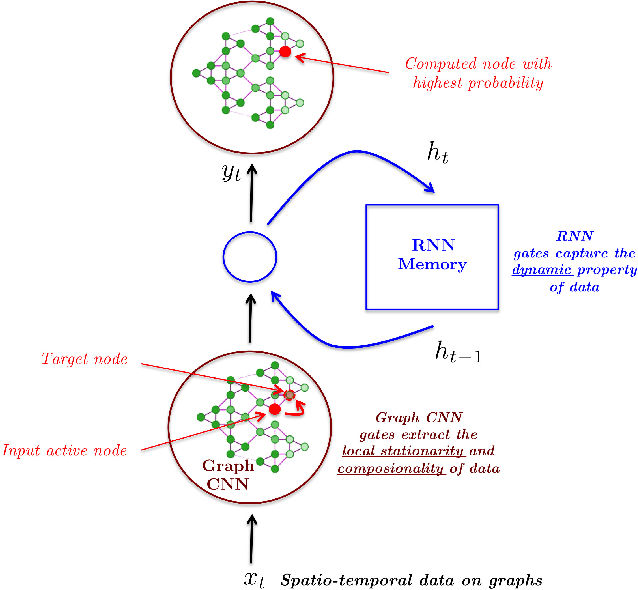
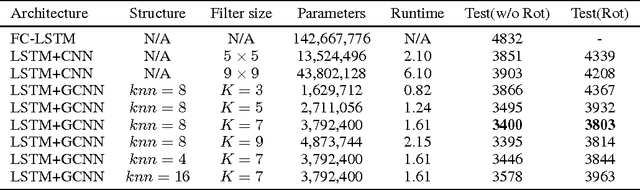
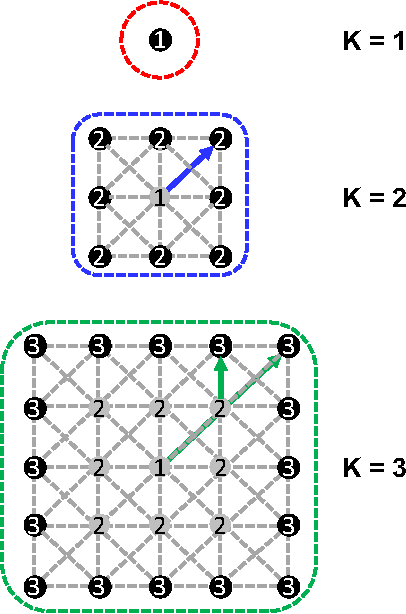
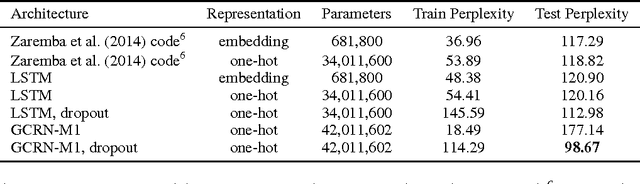
This paper introduces Graph Convolutional Recurrent Network (GCRN), a deep learning model able to predict structured sequences of data. Precisely, GCRN is a generalization of classical recurrent neural networks (RNN) to data structured by an arbitrary graph. Such structured sequences can represent series of frames in videos, spatio-temporal measurements on a network of sensors, or random walks on a vocabulary graph for natural language modeling. The proposed model combines convolutional neural networks (CNN) on graphs to identify spatial structures and RNN to find dynamic patterns. We study two possible architectures of GCRN, and apply the models to two practical problems: predicting moving MNIST data, and modeling natural language with the Penn Treebank dataset. Experiments show that exploiting simultaneously graph spatial and dynamic information about data can improve both precision and learning speed.
Deep Attribute Networks
Nov 28, 2012
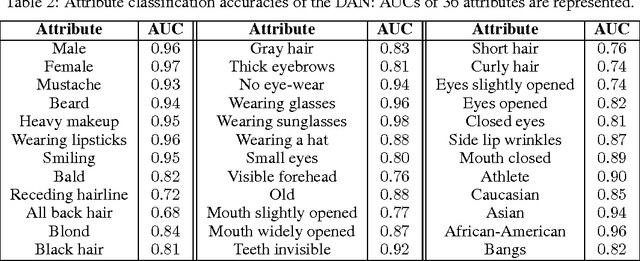
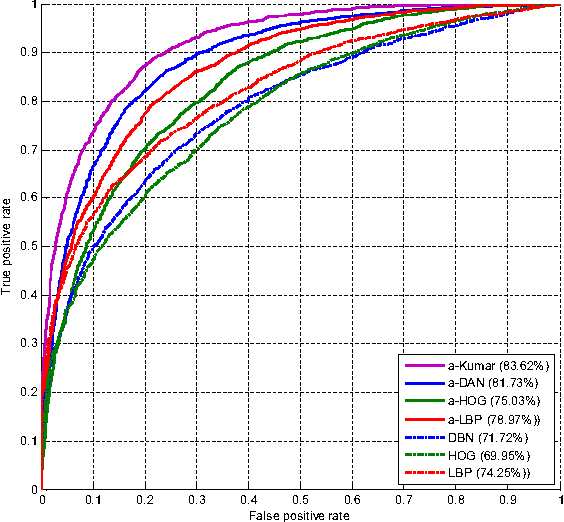
Obtaining compact and discriminative features is one of the major challenges in many of the real-world image classification tasks such as face verification and object recognition. One possible approach is to represent input image on the basis of high-level features that carry semantic meaning which humans can understand. In this paper, a model coined deep attribute network (DAN) is proposed to address this issue. For an input image, the model outputs the attributes of the input image without performing any classification. The efficacy of the proposed model is evaluated on unconstrained face verification and real-world object recognition tasks using the LFW and the a-PASCAL datasets. We demonstrate the potential of deep learning for attribute-based classification by showing comparable results with existing state-of-the-art results. Once properly trained, the DAN is fast and does away with calculating low-level features which are maybe unreliable and computationally expensive.