 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAC: Mining Activity Concepts for Language-based Temporal Localization
Paper and Code

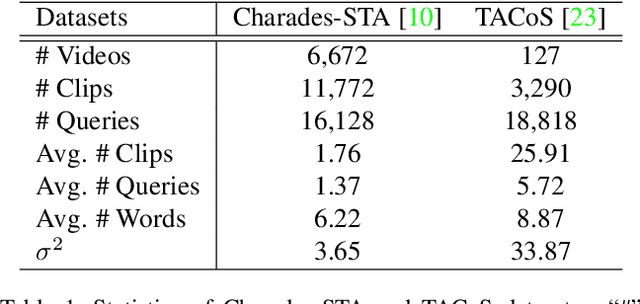

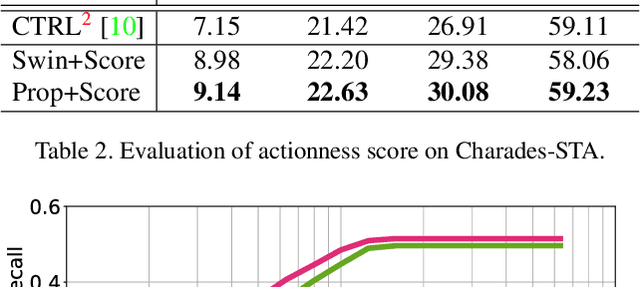
We address the problem of language-based temporal localization in untrimmed videos. Compared to temporal localization with fixed categories, this problem is more challenging as the language-based queries not only have no pre-defined activity list but also may contain complex descriptions. Previous methods address the problem by considering features from video sliding windows and language queries and learning a subspace to encode their correlation, which ignore rich semantic cues about activities in videos and queries. We propose to mine activity concepts from both video and language modalities by applying the actionness score enhanced Activity Concepts based Localizer (ACL). Specifically, the novel ACL encodes the semantic concepts from verb-obj pairs in language queries and leverages activity classifiers' prediction scores to encode visual concepts. Besides, ACL also has the capability to regress sliding windows as localization results. Experiments show that ACL significantly outperforms state-of-the-arts under the widely used metric, with more than 5% increase on both Charades-STA and TACoS datasets.