 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Guided Pruning for Efficient Hardware Implementations of Convolutional Neural Networks
Paper and Code
Dec 29, 2018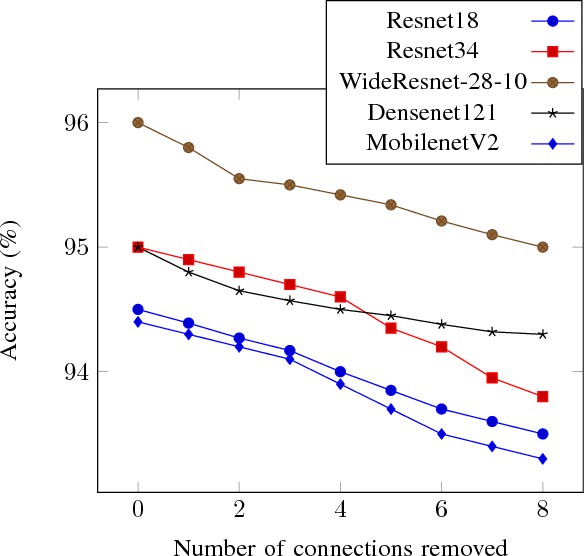
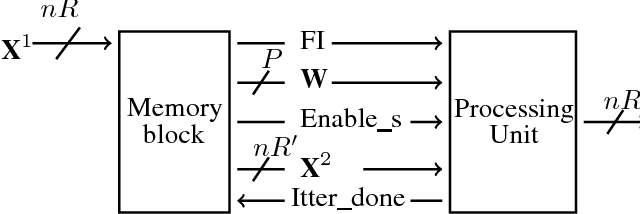
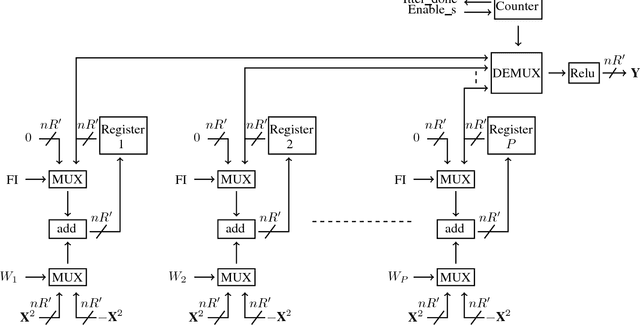
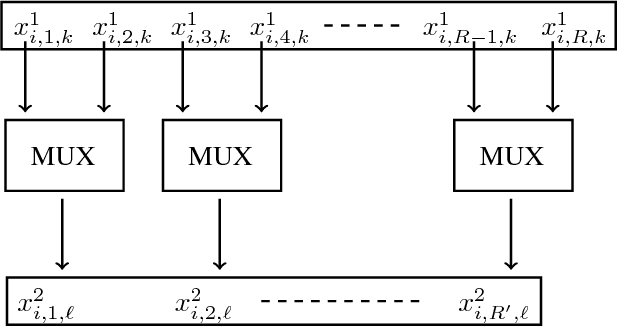
Convolutional Neural Networks (CNNs) are state-of-the-art in numerous computer vision tasks such as object classification and detection. However, the large amount of parameters they contain leads to a high computational complexity and strongly limits their usability in budget-constrained devices such as embedded devices. In this paper, we propose a combination of a new pruning technique and a quantization scheme that effectively reduce the complexity and memory usage of convolutional layers of CNNs, and replace the complex convolutional operation by a low-cost multiplexer. We perform experiments on the CIFAR10, CIFAR100 and SVHN and show that the proposed method achieves almost state-of-the-art accuracy, while drastically reducing the computational and memory footprints. We also propose an efficient hardware architecture to accelerate CNN operations. The proposed hardware architecture is a pipeline and accommodates multiple layers working at the same time to speed up the inference process.