 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Maximization for Long-Tailed Semi-Supervised Domain Generalization
Mar 09, 2026Semi-supervised domain generalization (SSDG) has recently emerged as an appealing alternative to tackle domain generalization when labeled data is scarce but unlabeled samples across domains are abundant. In this work, we identify an important limitation that hampers the deployment of state-of-the-art methods on more challenging but practical scenarios. In particular, state-of-the-art SSDG severely suffers in the presence of long-tailed class distributions, an arguably common situation in real-world settings. To alleviate this limitation, we propose IMaX, a simple yet effective objective based on the well-known InfoMax principle adapted to the SSDG scenario, where the Mutual Information (MI) between the learned features and latent labels is maximized, constrained by the supervision from the labeled samples. Our formulation integrates an α-entropic objective, which mitigates the class-balance bias encoded in the standard marginal entropy term of the MI, thereby better handling arbitrary class distributions. IMaX can be seamlessly plugged into recent state-of-the-art SSDG, consistently enhancing their performance, as demonstrated empirically across two different image modalities.
ORION: ORthonormal Text Encoding for Universal VLM AdaptatION
Feb 23, 2026Vision language models (VLMs) have demonstrated remarkable generalization across diverse tasks, yet their performance remains constrained by the quality and geometry of the textual prototypes used to represent classes. Standard zero shot classifiers, derived from frozen text encoders and handcrafted prompts, may yield correlated or weakly separated embeddings that limit task specific discriminability. We introduce ORION, a text encoder fine tuning framework that improves pretrained VLMs using only class names. Our method optimizes, via low rank adaptation, a novel loss integrating two terms, one promoting pairwise orthogonality between the textual representations of the classes of a given task and the other penalizing deviations from the initial class prototypes. Furthermore, we provide a probabilistic interpretation of our orthogonality penalty, connecting it to the general maximum likelihood estimation (MLE) principle via Huygens theorem. We report extensive experiments on 11 benchmarks and three large VLM backbones, showing that the refined textual embeddings yield powerful replacements for the standard CLIP prototypes. Added as plug and play module on top of various state of the art methods, and across different prediction settings (zero shot, few shot and test time adaptation), ORION improves the performance consistently and significantly.
SoC: Semantic Orthogonal Calibration for Test-Time Prompt Tuning
Jan 13, 2026With the increasing adoption of vision-language models (VLMs) in critical decision-making systems such as healthcare or autonomous driving, the calibration of their uncertainty estimates becomes paramount. Yet, this dimension has been largely underexplored in the VLM test-time prompt-tuning (TPT) literature, which has predominantly focused on improving their discriminative performance. Recent state-of-the-art advocates for enforcing full orthogonality over pairs of text prompt embeddings to enhance separability, and therefore calibration. Nevertheless, as we theoretically show in this work, the inherent gradients from fully orthogonal constraints will strongly push semantically related classes away, ultimately making the model overconfident. Based on our findings, we propose Semantic Orthogonal Calibration (SoC), a Huber-based regularizer that enforces smooth prototype separation while preserving semantic proximity, thereby improving calibration compared to prior orthogonality-based approaches. Across a comprehensive empirical validation, we demonstrate that SoC consistently improves calibration performance, while also maintaining competitive discriminative capabilities.
SITAR: Semi-supervised Image Transformer for Action Recognition
Sep 04, 2024

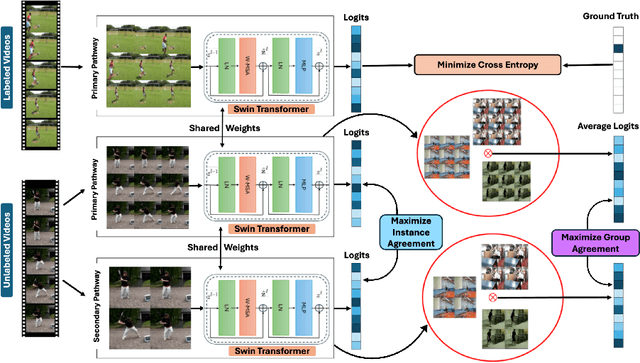

Recognizing actions from a limited set of labeled videos remains a challenge as annotating visual data is not only tedious but also can be expensive due to classified nature. Moreover, handling spatio-temporal data using deep $3$D transformers for this can introduce significant computational complexity. In this paper, our objective is to address video action recognition in a semi-supervised setting by leveraging only a handful of labeled videos along with a collection of unlabeled videos in a compute efficient manner. Specifically, we rearrange multiple frames from the input videos in row-column form to construct super images. Subsequently, we capitalize on the vast pool of unlabeled samples and employ contrastive learning on the encoded super images. Our proposed approach employs two pathways to generate representations for temporally augmented super images originating from the same video. Specifically, we utilize a 2D image-transformer to generate representations and apply a contrastive loss function to minimize the similarity between representations from different videos while maximizing the representations of identical videos. Our method demonstrates superior performance compared to existing state-of-the-art approaches for semi-supervised action recognition across various benchmark datasets, all while significantly reducing computational costs.
Semi-Supervised Action Recognition with Temporal Contrastive Learning
Feb 04, 2021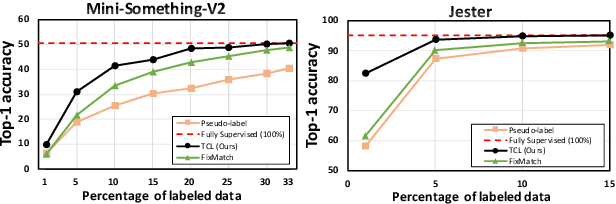
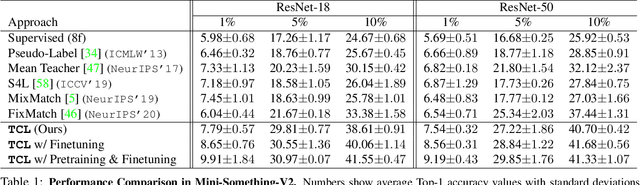
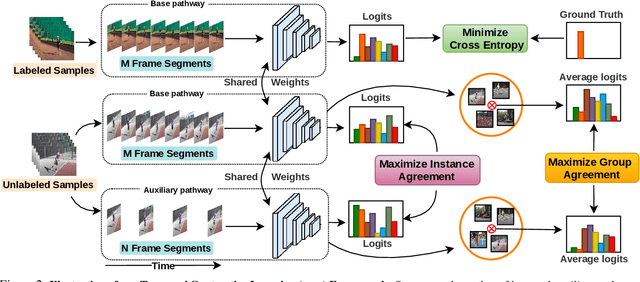
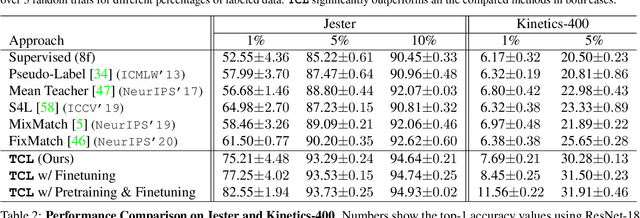
Learning to recognize actions from only a handful of labeled videos is a challenging problem due to the scarcity of tediously collected activity labels. We approach this problem by learning a two-pathway temporal contrastive model using unlabeled videos at two different speeds leveraging the fact that changing video speed does not change an action. Specifically, we propose to maximize the similarity between encoded representations of the same video at two different speeds as well as minimize the similarity between different videos played at different speeds. This way we use the rich supervisory information in terms of 'time' that is present in otherwise unsupervised pool of videos. With this simple yet effective strategy of manipulating video playback rates, we considerably outperform video extensions of sophisticated state-of-the-art semi-supervised image recognition methods across multiple diverse benchmark datasets and network architectures. Interestingly, our proposed approach benefits from out-of-domain unlabeled videos showing generalization and robustness. We also perform rigorous ablations and analysis to validate our approach.