 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Image Segmentation: Grounding Abstract Concepts with Scalable Supervision
Feb 13, 2026Conversational image segmentation grounds abstract, intent-driven concepts into pixel-accurate masks. Prior work on referring image grounding focuses on categorical and spatial queries (e.g., "left-most apple") and overlooks functional and physical reasoning (e.g., "where can I safely store the knife?"). We address this gap and introduce Conversational Image Segmentation (CIS) and ConverSeg, a benchmark spanning entities, spatial relations, intent, affordances, functions, safety, and physical reasoning. We also present ConverSeg-Net, which fuses strong segmentation priors with language understanding, and an AI-powered data engine that generates prompt-mask pairs without human supervision. We show that current language-guided segmentation models are inadequate for CIS, while ConverSeg-Net trained on our data engine achieves significant gains on ConverSeg and maintains strong performance on existing language-guided segmentation benchmarks. Project webpage: https://glab-caltech.github.io/converseg/
Aligning Text, Images, and 3D Structure Token-by-Token
Jun 09, 2025



Creating machines capable of understanding the world in 3D is essential in assisting designers that build and edit 3D environments and robots navigating and interacting within a three-dimensional space. Inspired by advances in language and image modeling, we investigate the potential of autoregressive models for a new modality: structured 3D scenes. To this end, we propose a unified LLM framework that aligns language, images, and 3D scenes and provide a detailed ''cookbook'' outlining critical design choices for achieving optimal training and performance addressing key questions related to data representation, modality-specific objectives, and more. We evaluate performance across four core 3D tasks -- rendering, recognition, instruction-following, and question-answering -- and four 3D datasets, synthetic and real-world. We extend our approach to reconstruct complex 3D object shapes by enriching our 3D modality with quantized shape encodings, and show our model's effectiveness on real-world 3D object recognition tasks. Project webpage: https://glab-caltech.github.io/kyvo/
Contrast and Mix: Temporal Contrastive Video Domain Adaptation with Background Mixing
Oct 28, 2021
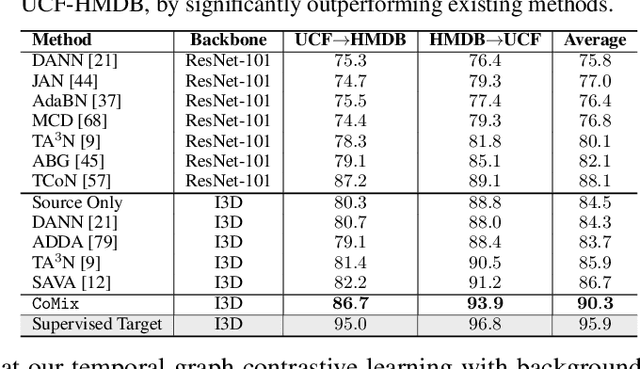

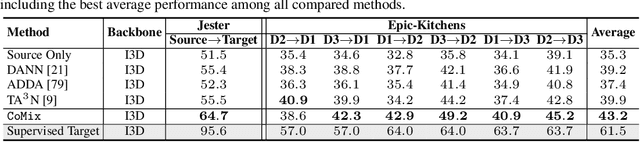
Unsupervised domain adaptation which aims to adapt models trained on a labeled source domain to a completely unlabeled target domain has attracted much attention in recent years. While many domain adaptation techniques have been proposed for images, the problem of unsupervised domain adaptation in videos remains largely underexplored. In this paper, we introduce Contrast and Mix (CoMix), a new contrastive learning framework that aims to learn discriminative invariant feature representations for unsupervised video domain adaptation. First, unlike existing methods that rely on adversarial learning for feature alignment, we utilize temporal contrastive learning to bridge the domain gap by maximizing the similarity between encoded representations of an unlabeled video at two different speeds as well as minimizing the similarity between different videos played at different speeds. Second, we propose a novel extension to the temporal contrastive loss by using background mixing that allows additional positives per anchor, thus adapting contrastive learning to leverage action semantics shared across both domains. Moreover, we also integrate a supervised contrastive learning objective using target pseudo-labels to enhance discriminability of the latent space for video domain adaptation. Extensive experiments on several benchmark datasets demonstrate the superiority of our proposed approach over state-of-the-art methods. Project page: https://cvir.github.io/projects/comix
Select, Label, and Mix: Learning Discriminative Invariant Feature Representations for Partial Domain Adaptation
Dec 06, 2020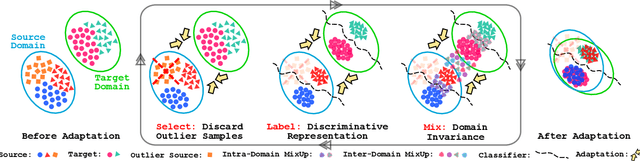
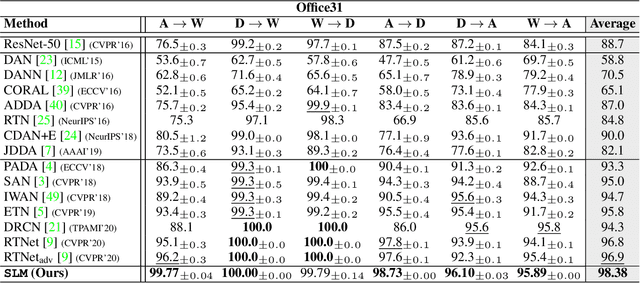
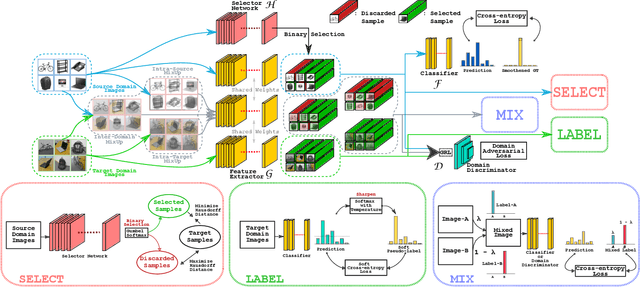
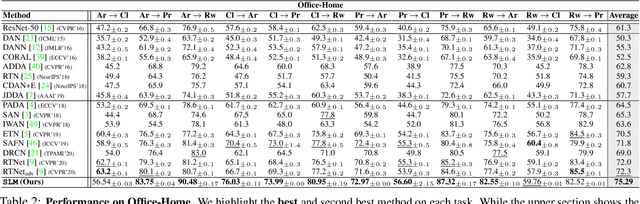
Partial domain adaptation which assumes that the unknown target label space is a subset of the source label space has attracted much attention in computer vision. Despite recent progress, existing methods often suffer from three key problems: negative transfer, lack of discriminability and domain invariance in the latent space. To alleviate the above issues, we develop a novel 'Select, Label, and Mix' (SLM) framework that aims to learn discriminative invariant feature representations for partial domain adaptation. First, we present a simple yet efficient "select" module that automatically filters out the outlier source samples to avoid negative transfer while aligning distributions across both domains. Second, the "label" module iteratively trains the classifier using both the labeled source domain data and the generated pseudo-labels for the target domain to enhance the discriminability of the latent space. Finally, the "mix" module utilizes domain mixup regularization jointly with the other two modules to explore more intrinsic structures across domains leading to a domain-invariant latent space for partial domain adaptation. Extensive experiments on several benchmark datasets demonstrate the superiority of our proposed framework over state-of-the-art methods.
Mitigating Dataset Imbalance via Joint Generation and Classification
Aug 12, 2020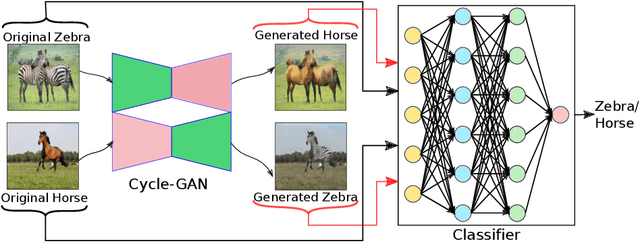
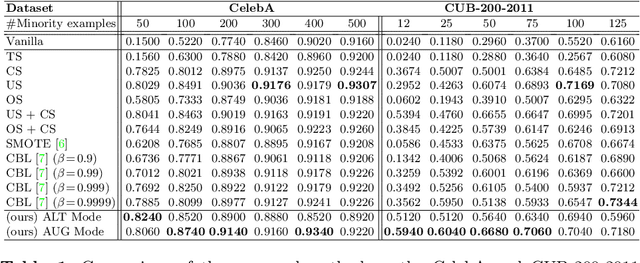
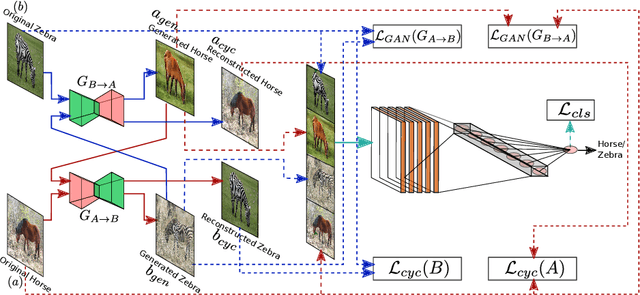
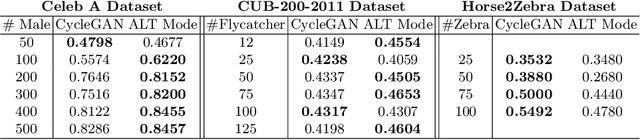
Supervised deep learning methods are enjoying enormous success in many practical applications of computer vision and have the potential to revolutionize robotics. However, the marked performance degradation to biases and imbalanced data questions the reliability of these methods. In this work we address these questions from the perspective of dataset imbalance resulting out of severe under-representation of annotated training data for certain classes and its effect on both deep classification and generation methods. We introduce a joint dataset repairment strategy by combining a neural network classifier with Generative Adversarial Networks (GAN) that makes up for the deficit of training examples from the under-representated class by producing additional training examples. We show that the combined training helps to improve the robustness of both the classifier and the GAN against severe class imbalance. We show the effectiveness of our proposed approach on three very different datasets with different degrees of imbalance in them. The code is available at https://github.com/AadSah/ImbalanceCycleGAN .