 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Source and Target Contributions to Predictions in Neural Machine Translation
Paper and Code
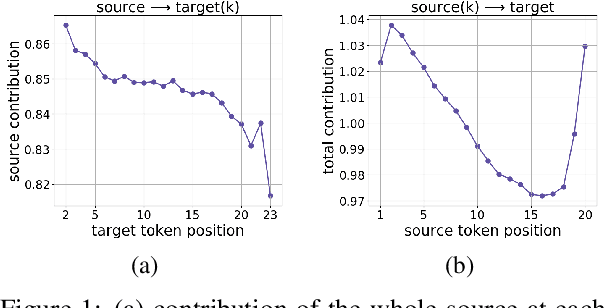
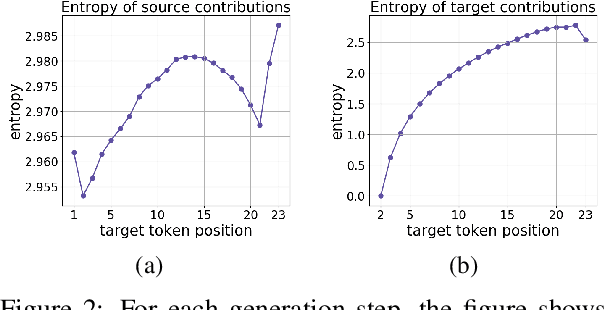
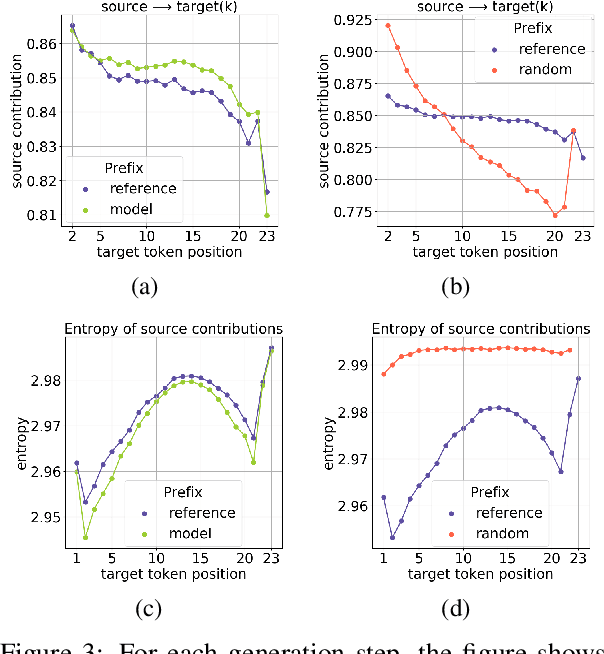
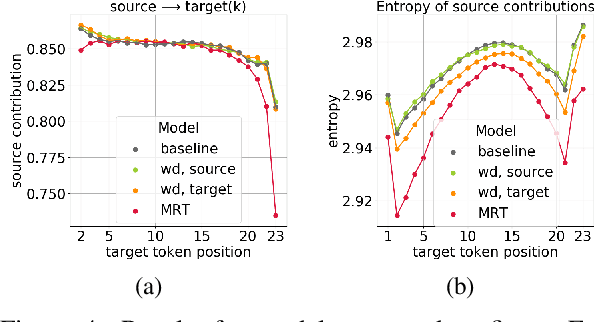
In Neural Machine Translation (and, more generally, conditional language modeling), the generation of a target token is influenced by two types of context: the source and the prefix of the target sequence. While many attempts to understand the internal workings of NMT models have been made, none of them explicitly evaluates relative source and target contributions to a generation decision. We argue that this relative contribution can be evaluated by adopting a variant of Layerwise Relevance Propagation (LRP). Its underlying 'conservation principle' makes relevance propagation unique: differently from other methods, it evaluates not an abstract quantity reflecting token importance, but the proportion of each token's influence. We extend LRP to the Transformer and conduct an analysis of NMT models which explicitly evaluates the source and target relative contributions to the generation process. We analyze changes in these contributions when conditioning on different types of prefixes, when varying the training objective or the amount of training data, and during the training process. We find that models trained with more data tend to rely on source information more and to have more sharp token contributions; the training process is non-monotonic with several stages of different nature.