 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
Paper and Code
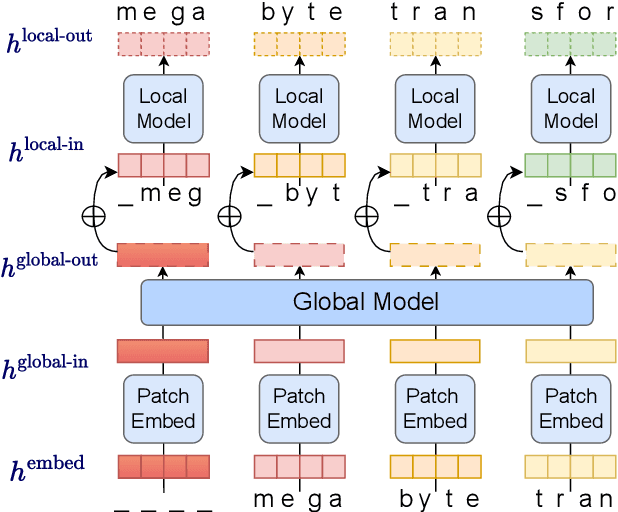


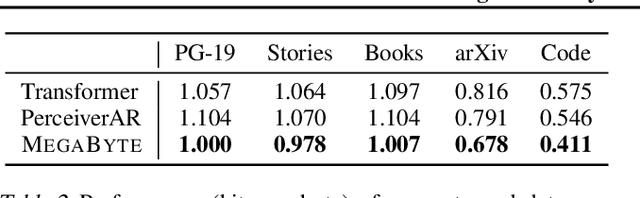
Autoregressive transformers are spectacular models for short sequences but scale poorly to long sequences such as high-resolution images, podcasts, code, or books. We proposed Megabyte, a multi-scale decoder architecture that enables end-to-end differentiable modeling of sequences of over one million bytes. Megabyte segments sequences into patches and uses a local submodel within patches and a global model between patches. This enables sub-quadratic self-attention, much larger feedforward layers for the same compute, and improved parallelism during decoding -- unlocking better performance at reduced cost for both training and generation. Extensive experiments show that Megabyte allows byte-level models to perform competitively with subword models on long context language modeling, achieve state-of-the-art density estimation on ImageNet, and model audio from raw files. Together, these results establish the viability of tokenization-free autoregressive sequence modeling at scale.