 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWARP: Word-level Adversarial ReProgramming
Paper and Code
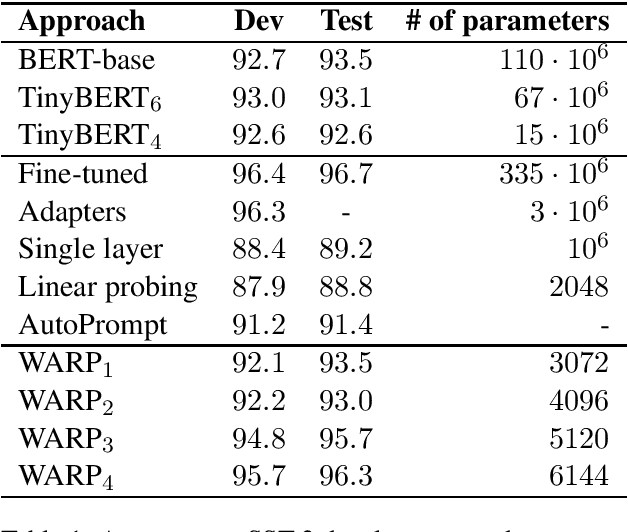
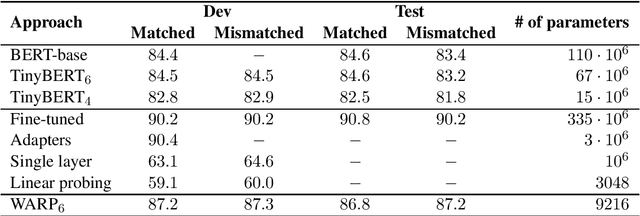

Transfer learning from pretrained language models recently became the dominant approach for solving many NLP tasks. While fine-tuning large language models usually gives the best performance, in many applications it is preferable to tune much smaller sets of parameters, so that the majority of parameters can be shared across multiple tasks. The main approach is to train one or more task-specific layers on top of the language model. In this paper we present an alternative approach based on adversarial reprogramming, which extends earlier work on automatic prompt generation. It attempts to learn task-specific word embeddings that, when concatenated to the input text, instruct the language model to solve the specified task. We show that this approach outperforms other methods with a similar number of trainable parameters on SST-2 and MNLI datasets. On SST-2, the performance of our model is comparable to the fully fine-tuned baseline, while on MNLI it is the best among the methods that do not modify the parameters of the body of the language model.