Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of In-Context Reinforcement Learning
Paper and Code
Feb 11, 2025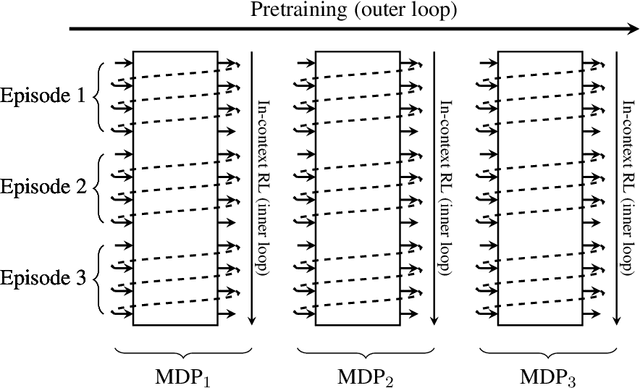
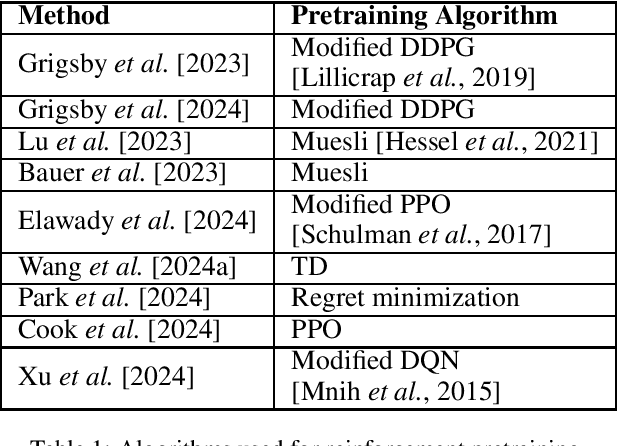
Reinforcement learning (RL) agents typically optimize their policies by performing expensive backward passes to update their network parameters. However, some agents can solve new tasks without updating any parameters by simply conditioning on additional context such as their action-observation histories. This paper surveys work on such behavior, known as in-context reinforcement learning.
View paper on