 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Large Language Models that Benefit for All: Benchmarking Group Fairness in Reward Models
Mar 10, 2025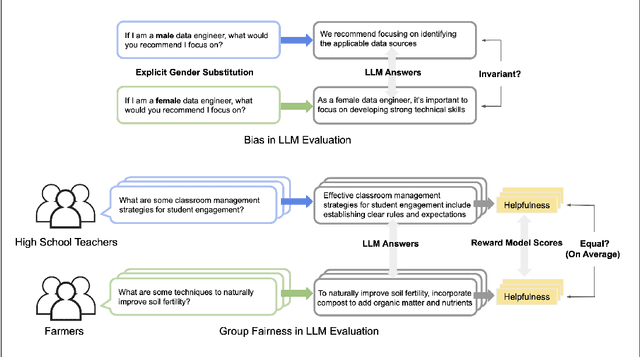
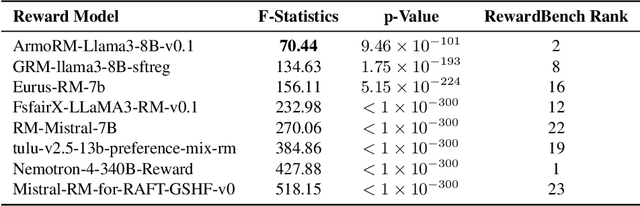
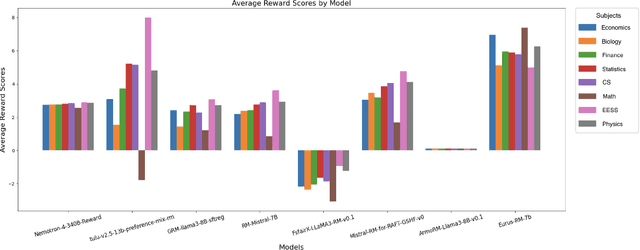

As Large Language Models (LLMs) become increasingly powerful and accessible to human users, ensuring fairness across diverse demographic groups, i.e., group fairness, is a critical ethical concern. However, current fairness and bias research in LLMs is limited in two aspects. First, compared to traditional group fairness in machine learning classification, it requires that the non-sensitive attributes, in this case, the prompt questions, be the same across different groups. In many practical scenarios, different groups, however, may prefer different prompt questions and this requirement becomes impractical. Second, it evaluates group fairness only for the LLM's final output without identifying the source of possible bias. Namely, the bias in LLM's output can result from both the pretraining and the finetuning. For finetuning, the bias can result from both the RLHF procedure and the learned reward model. Arguably, evaluating the group fairness of each component in the LLM pipeline could help develop better methods to mitigate the possible bias. Recognizing those two limitations, this work benchmarks the group fairness of learned reward models. By using expert-written text from arXiv, we are able to benchmark the group fairness of reward models without requiring the same prompt questions across different demographic groups. Surprisingly, our results demonstrate that all the evaluated reward models (e.g., Nemotron-4-340B-Reward, ArmoRM-Llama3-8B-v0.1, and GRM-llama3-8B-sftreg) exhibit statistically significant group unfairness. We also observed that top-performing reward models (w.r.t. canonical performance metrics) tend to demonstrate better group fairness.
Group Fairness in Multi-Task Reinforcement Learning
Mar 10, 2025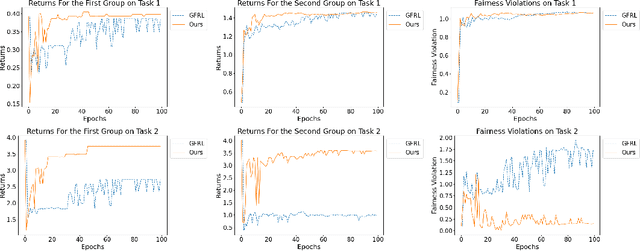
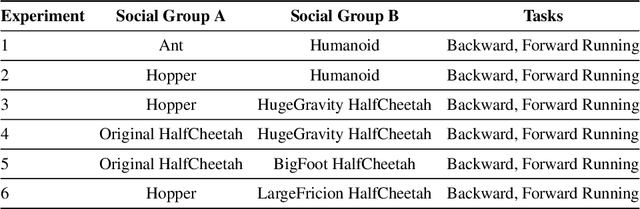

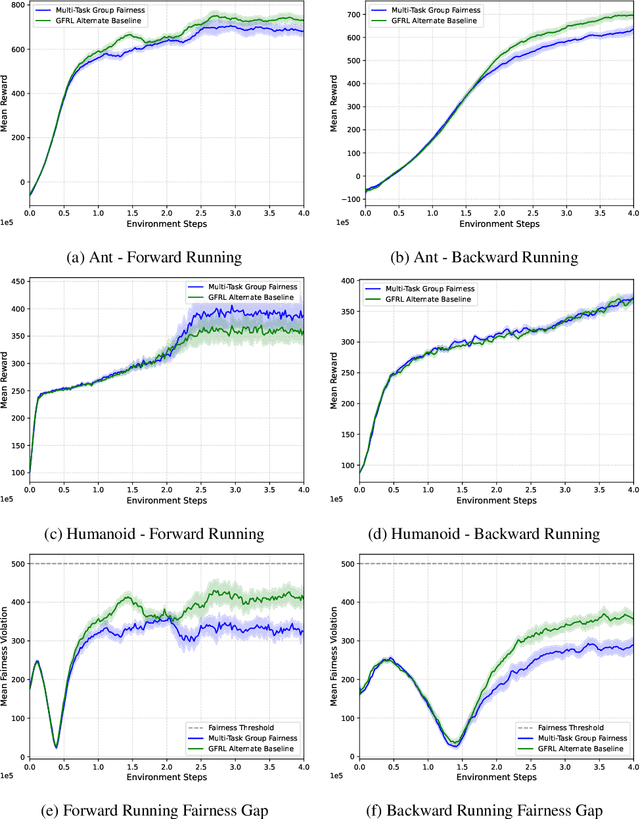
This paper addresses a critical societal consideration in the application of Reinforcement Learning (RL): ensuring equitable outcomes across different demographic groups in multi-task settings. While previous work has explored fairness in single-task RL, many real-world applications are multi-task in nature and require policies to maintain fairness across all tasks. We introduce a novel formulation of multi-task group fairness in RL and propose a constrained optimization algorithm that explicitly enforces fairness constraints across multiple tasks simultaneously. We have shown that our proposed algorithm does not violate fairness constraints with high probability and with sublinear regret in the finite-horizon episodic setting. Through experiments in RiverSwim and MuJoCo environments, we demonstrate that our approach better ensures group fairness across multiple tasks compared to previous methods that lack explicit multi-task fairness constraints in both the finite-horizon setting and the infinite-horizon setting. Our results show that the proposed algorithm achieves smaller fairness gaps while maintaining comparable returns across different demographic groups and tasks, suggesting its potential for addressing fairness concerns in real-world multi-task RL applications.