 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Inference and Reduced Forgetting: The Dual Benefits of Early-Exit Networks in Continual Learning
Paper and Code
Mar 12, 2024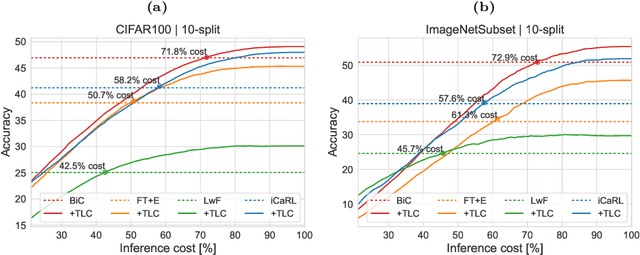
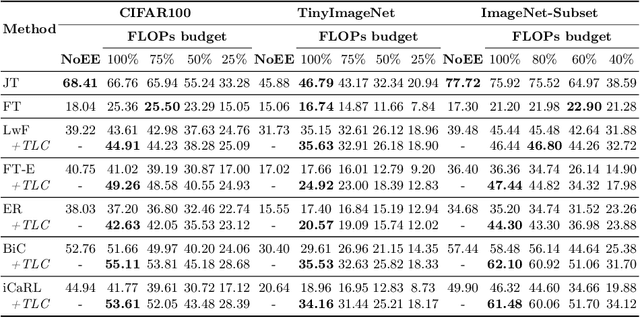
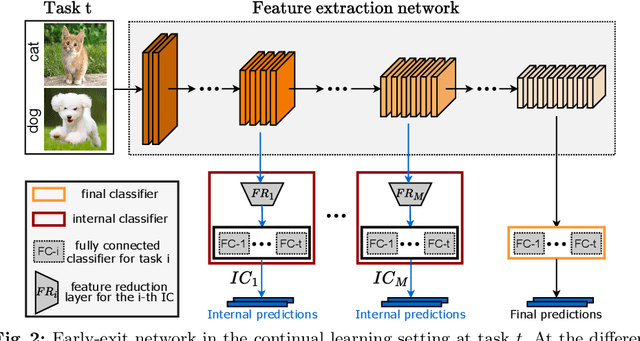
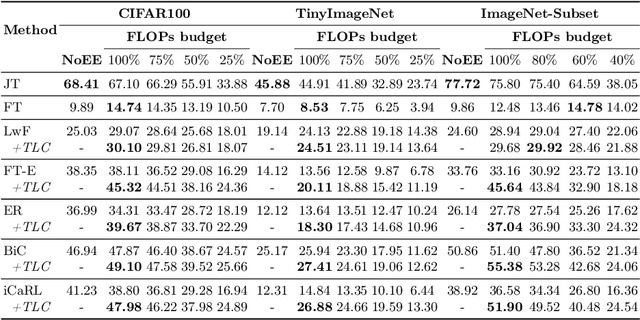
Driven by the demand for energy-efficient employment of deep neural networks, early-exit methods have experienced a notable increase in research attention. These strategies allow for swift predictions by making decisions early in the network, thereby conserving computation time and resources. However, so far the early-exit networks have only been developed for stationary data distributions, which restricts their application in real-world scenarios with continuous non-stationary data. This study aims to explore the continual learning of the early-exit networks. We adapt existing continual learning methods to fit with early-exit architectures and investigate their behavior in the continual setting. We notice that early network layers exhibit reduced forgetting and can outperform standard networks even when using significantly fewer resources. Furthermore, we analyze the impact of task-recency bias on early-exit inference and propose Task-wise Logits Correction (TLC), a simple method that equalizes this bias and improves the network performance for every given compute budget in the class-incremental setting. We assess the accuracy and computational cost of various continual learning techniques enhanced with early-exits and TLC across standard class-incremental learning benchmarks such as 10 split CIFAR100 and ImageNetSubset and show that TLC can achieve the accuracy of the standard methods using less than 70\% of their computations. Moreover, at full computational budget, our method outperforms the accuracy of the standard counterparts by up to 15 percentage points. Our research underscores the inherent synergy between early-exit networks and continual learning, emphasizing their practical utility in resource-constrained environments.