 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversalization of any adversarial attack using very few test examples
Paper and Code
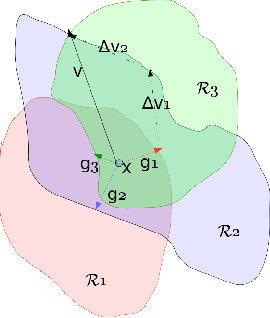
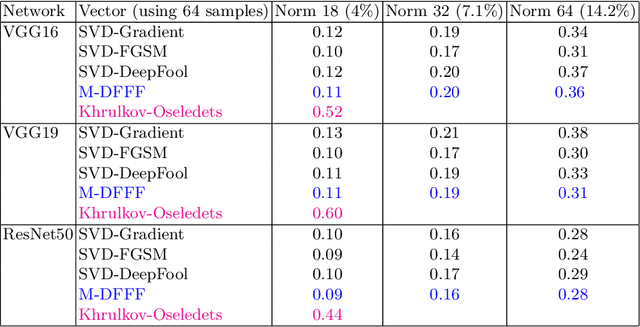

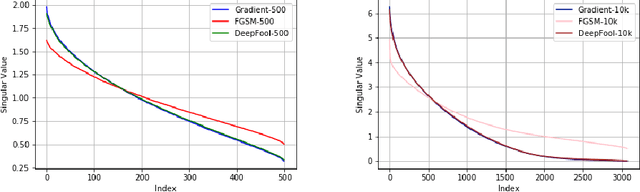
Deep learning models are known to be vulnerable not only to input-dependent adversarial attacks but also to input-agnostic or universal adversarial attacks. Dezfooli et al. \cite{Dezfooli17,Dezfooli17anal} construct universal adversarial attack on a given model by looking at a large number of training data points and the geometry of the decision boundary near them. Subsequent work \cite{Khrulkov18} constructs universal attack by looking only at test examples and intermediate layers of the given model. In this paper, we propose a simple universalization technique to take any input-dependent adversarial attack and construct a universal attack by only looking at very few adversarial test examples. We do not require details of the given model and have negligible computational overhead for universalization. We theoretically justify our universalization technique by a spectral property common to many input-dependent adversarial perturbations, e.g., gradients, Fast Gradient Sign Method (FGSM) and DeepFool. Using matrix concentration inequalities and spectral perturbation bounds, we show that the top singular vector of input-dependent adversarial directions on a small test sample gives an effective and simple universal adversarial attack. For VGG16 and VGG19 models trained on ImageNet, our simple universalization of Gradient, FGSM, and DeepFool perturbations using a test sample of 64 images gives fooling rates comparable to state-of-the-art universal attacks \cite{Dezfooli17,Khrulkov18} for reasonable norms of perturbation.