 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Compressed Embeddings for On-Device Inference
Mar 18, 2022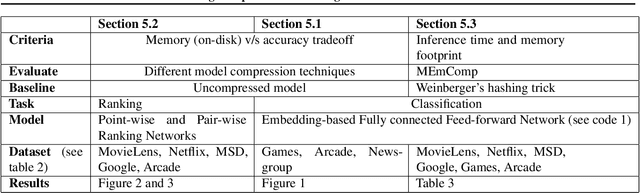
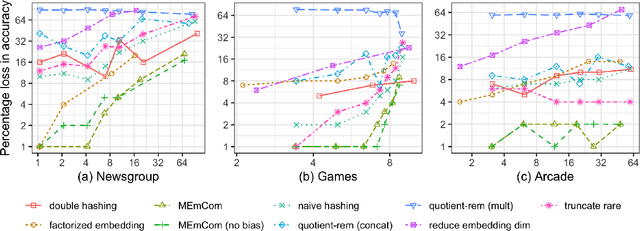
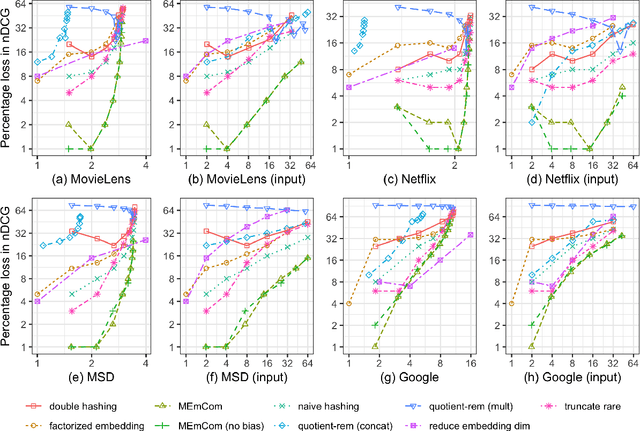

In deep learning, embeddings are widely used to represent categorical entities such as words, apps, and movies. An embedding layer maps each entity to a unique vector, causing the layer's memory requirement to be proportional to the number of entities. In the recommendation domain, a given category can have hundreds of thousands of entities, and its embedding layer can take gigabytes of memory. The scale of these networks makes them difficult to deploy in resource constrained environments. In this paper, we propose a novel approach for reducing the size of an embedding table while still mapping each entity to its own unique embedding. Rather than maintaining the full embedding table, we construct each entity's embedding "on the fly" using two separate embedding tables. The first table employs hashing to force multiple entities to share an embedding. The second table contains one trainable weight per entity, allowing the model to distinguish between entities sharing the same embedding. Since these two tables are trained jointly, the network is able to learn a unique embedding per entity, helping it maintain a discriminative capability similar to a model with an uncompressed embedding table. We call this approach MEmCom (Multi-Embedding Compression). We compare with state-of-the-art model compression techniques for multiple problem classes including classification and ranking. On four popular recommender system datasets, MEmCom had a 4% relative loss in nDCG while compressing the input embedding sizes of our recommendation models by 16x, 4x, 12x, and 40x. MEmCom outperforms the state-of-the-art techniques, which achieved 16%, 6%, 10%, and 8% relative loss in nDCG at the respective compression ratios. Additionally, MEmCom is able to compress the RankNet ranking model by 32x on a dataset with millions of users' interactions with games while incurring only a 1% relative loss in nDCG.