 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable ML Feature Engineering via Planning in Constrained-Topology of LLM Agents
Jan 15, 2026Recent advances in code generation models have unlocked unprecedented opportunities for automating feature engineering, yet their adoption in real-world ML teams remains constrained by critical challenges: (i) the scarcity of datasets capturing the iterative and complex coding processes of production-level feature engineering, (ii) limited integration and personalization of widely used coding agents, such as CoPilot and Devin, with a team's unique tools, codebases, workflows, and practices, and (iii) suboptimal human-AI collaboration due to poorly timed or insufficient feedback. We address these challenges with a planner-guided, constrained-topology multi-agent framework that generates code for repositories in a multi-step fashion. The LLM-powered planner leverages a team's environment, represented as a graph, to orchestrate calls to available agents, generate context-aware prompts, and use downstream failures to retroactively correct upstream artifacts. It can request human intervention at critical steps, ensuring generated code is reliable, maintainable, and aligned with team expectations. On a novel in-house dataset, our approach achieves 38% and 150% improvement in the evaluation metric over manually crafted and unplanned workflows respectively. In practice, when building features for recommendation models serving over 120 million users, our approach has delivered real-world impact by reducing feature engineering cycles from three weeks to a single day.
ProbFM: Probabilistic Time Series Foundation Model with Uncertainty Decomposition
Jan 15, 2026Time Series Foundation Models (TSFMs) have emerged as a promising approach for zero-shot financial forecasting, demonstrating strong transferability and data efficiency gains. However, their adoption in financial applications is hindered by fundamental limitations in uncertainty quantification: current approaches either rely on restrictive distributional assumptions, conflate different sources of uncertainty, or lack principled calibration mechanisms. While recent TSFMs employ sophisticated techniques such as mixture models, Student's t-distributions, or conformal prediction, they fail to address the core challenge of providing theoretically-grounded uncertainty decomposition. For the very first time, we present a novel transformer-based probabilistic framework, ProbFM (probabilistic foundation model), that leverages Deep Evidential Regression (DER) to provide principled uncertainty quantification with explicit epistemic-aleatoric decomposition. Unlike existing approaches that pre-specify distributional forms or require sampling-based inference, ProbFM learns optimal uncertainty representations through higher-order evidence learning while maintaining single-pass computational efficiency. To rigorously evaluate the core DER uncertainty quantification approach independent of architectural complexity, we conduct an extensive controlled comparison study using a consistent LSTM architecture across five probabilistic methods: DER, Gaussian NLL, Student's-t NLL, Quantile Loss, and Conformal Prediction. Evaluation on cryptocurrency return forecasting demonstrates that DER maintains competitive forecasting accuracy while providing explicit epistemic-aleatoric uncertainty decomposition. This work establishes both an extensible framework for principled uncertainty quantification in foundation models and empirical evidence for DER's effectiveness in financial applications.
Learning Compressed Embeddings for On-Device Inference
Mar 18, 2022
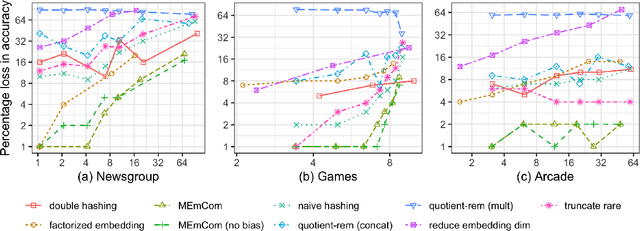
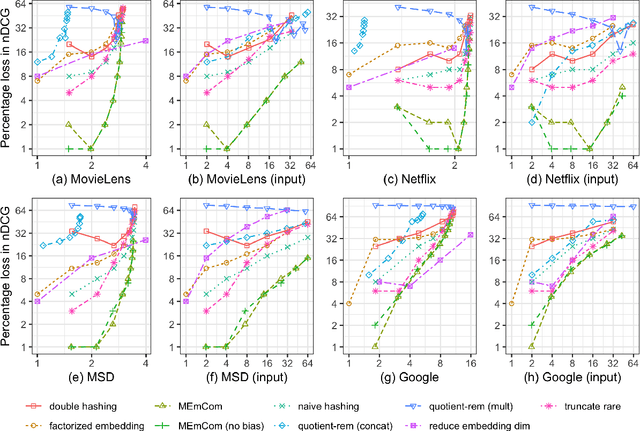

In deep learning, embeddings are widely used to represent categorical entities such as words, apps, and movies. An embedding layer maps each entity to a unique vector, causing the layer's memory requirement to be proportional to the number of entities. In the recommendation domain, a given category can have hundreds of thousands of entities, and its embedding layer can take gigabytes of memory. The scale of these networks makes them difficult to deploy in resource constrained environments. In this paper, we propose a novel approach for reducing the size of an embedding table while still mapping each entity to its own unique embedding. Rather than maintaining the full embedding table, we construct each entity's embedding "on the fly" using two separate embedding tables. The first table employs hashing to force multiple entities to share an embedding. The second table contains one trainable weight per entity, allowing the model to distinguish between entities sharing the same embedding. Since these two tables are trained jointly, the network is able to learn a unique embedding per entity, helping it maintain a discriminative capability similar to a model with an uncompressed embedding table. We call this approach MEmCom (Multi-Embedding Compression). We compare with state-of-the-art model compression techniques for multiple problem classes including classification and ranking. On four popular recommender system datasets, MEmCom had a 4% relative loss in nDCG while compressing the input embedding sizes of our recommendation models by 16x, 4x, 12x, and 40x. MEmCom outperforms the state-of-the-art techniques, which achieved 16%, 6%, 10%, and 8% relative loss in nDCG at the respective compression ratios. Additionally, MEmCom is able to compress the RankNet ranking model by 32x on a dataset with millions of users' interactions with games while incurring only a 1% relative loss in nDCG.