 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Line of Sight Defense Communication Systems: Recent Advances and Future Challenges
Dec 11, 2023Beyond Line of Sight (BLOS) communication stands as an indispensable element within defense communication strategies, facilitating information exchange in scenarios where traditional Line of Sight (LOS) methodologies encounter obstruction. This article delves into the forefront of technologies driving BLOS communication, emphasizing advanced systems like phantom networks, nanonetworks, aerial relays, and satellite-based defense communication. Moreover, we present a practical use case of UAV path planning using optimization techniques amidst radar-threat war zones that add concrete relevance, underscoring the tangible applications of BLOS defense communication systems. Additionally, we present several future research directions for BLOS communication in defense systems, such as resilience enhancement, the integration of heterogeneous networks, management of contested spectrums, advancements in multimedia communication, adaptive methodologies, and the burgeoning domain of the Internet of Military Things (IoMT). This exploration of BLOS technologies and their applications lays the groundwork for synergistic collaboration between industry and academia, fostering innovation in defense communication paradigms.
The Digitalization of Bioassays in the Open Research Knowledge Graph
Mar 28, 2022


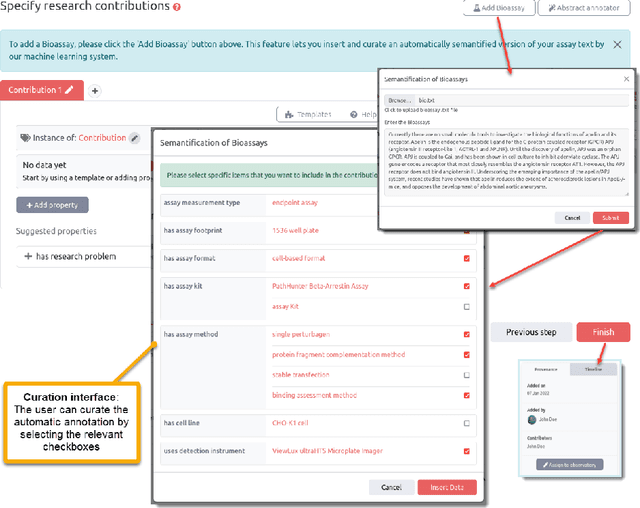
Background: Recent years are seeing a growing impetus in the semantification of scholarly knowledge at the fine-grained level of scientific entities in knowledge graphs. The Open Research Knowledge Graph (ORKG) https://www.orkg.org/ represents an important step in this direction, with thousands of scholarly contributions as structured, fine-grained, machine-readable data. There is a need, however, to engender change in traditional community practices of recording contributions as unstructured, non-machine-readable text. For this in turn, there is a strong need for AI tools designed for scientists that permit easy and accurate semantification of their scholarly contributions. We present one such tool, ORKG-assays. Implementation: ORKG-assays is a freely available AI micro-service in ORKG written in Python designed to assist scientists obtain semantified bioassays as a set of triples. It uses an AI-based clustering algorithm which on gold-standard evaluations over 900 bioassays with 5,514 unique property-value pairs for 103 predicates shows competitive performance. Results and Discussion: As a result, semantified assay collections can be surveyed on the ORKG platform via tabulation or chart-based visualizations of key property values of the chemicals and compounds offering smart knowledge access to biochemists and pharmaceutical researchers in the advancement of drug development.
Low Light Image Enhancement via Global and Local Context Modeling
Jan 04, 2021
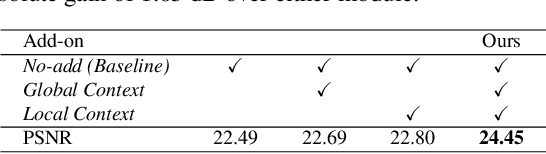
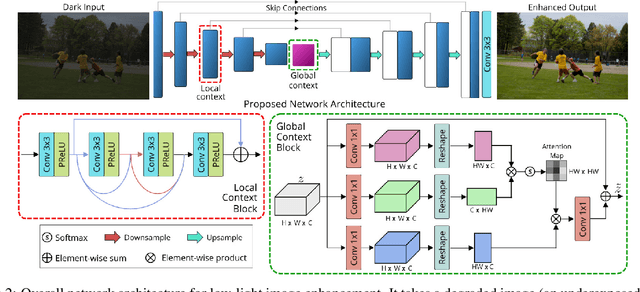

Images captured under low-light conditions manifest poor visibility, lack contrast and color vividness. Compared to conventional approaches, deep convolutional neural networks (CNNs) perform well in enhancing images. However, being solely reliant on confined fixed primitives to model dependencies, existing data-driven deep models do not exploit the contexts at various spatial scales to address low-light image enhancement. These contexts can be crucial towards inferring several image enhancement tasks, e.g., local and global contrast, brightness and color corrections; which requires cues from both local and global spatial extent. To this end, we introduce a context-aware deep network for low-light image enhancement. First, it features a global context module that models spatial correlations to find complementary cues over full spatial domain. Second, it introduces a dense residual block that captures local context with a relatively large receptive field. We evaluate the proposed approach using three challenging datasets: MIT-Adobe FiveK, LoL, and SID. On all these datasets, our method performs favorably against the state-of-the-arts in terms of standard image fidelity metrics. In particular, compared to the best performing method on the MIT-Adobe FiveK dataset, our algorithm improves PSNR from 23.04 dB to 24.45 dB.
Image Super-Resolution using Explicit Perceptual Loss
Sep 01, 2020
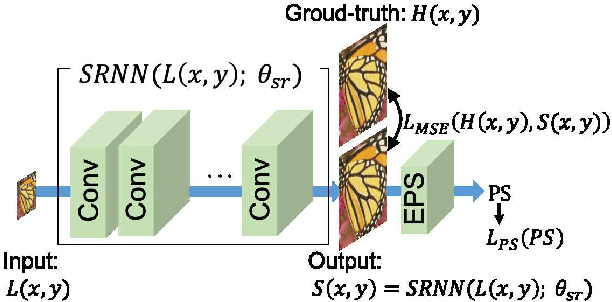

This paper proposes an explicit way to optimize the super-resolution network for generating visually pleasing images. The previous approaches use several loss functions which is hard to interpret and has the implicit relationships to improve the perceptual score. We show how to exploit the machine learning based model which is directly trained to provide the perceptual score on generated images. It is believed that these models can be used to optimizes the super-resolution network which is easier to interpret. We further analyze the characteristic of the existing loss and our proposed explicit perceptual loss for better interpretation. The experimental results show the explicit approach has a higher perceptual score than other approaches. Finally, we demonstrate the relation of explicit perceptual loss and visually pleasing images using subjective evaluation.
Space-Time-Aware Multi-Resolution Video Enhancement
Mar 30, 2020


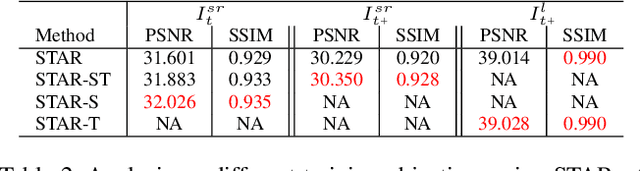
We consider the problem of space-time super-resolution (ST-SR): increasing spatial resolution of video frames and simultaneously interpolating frames to increase the frame rate. Modern approaches handle these axes one at a time. In contrast, our proposed model called STARnet super-resolves jointly in space and time. This allows us to leverage mutually informative relationships between time and space: higher resolution can provide more detailed information about motion, and higher frame-rate can provide better pixel alignment. The components of our model that generate latent low- and high-resolution representations during ST-SR can be used to finetune a specialized mechanism for just spatial or just temporal super-resolution. Experimental results demonstrate that STARnet improves the performances of space-time, spatial, and temporal video super-resolution by substantial margins on publicly available datasets.
Deep Back-Projection Networks for Single Image Super-resolution
Apr 04, 2019
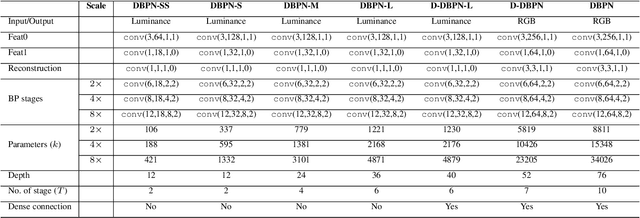
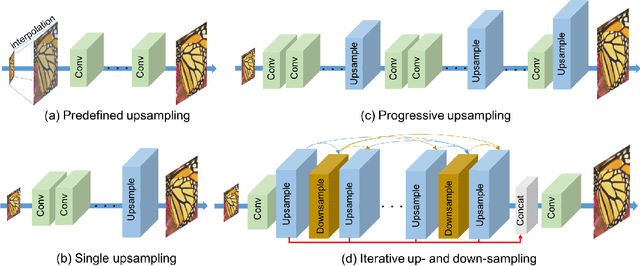
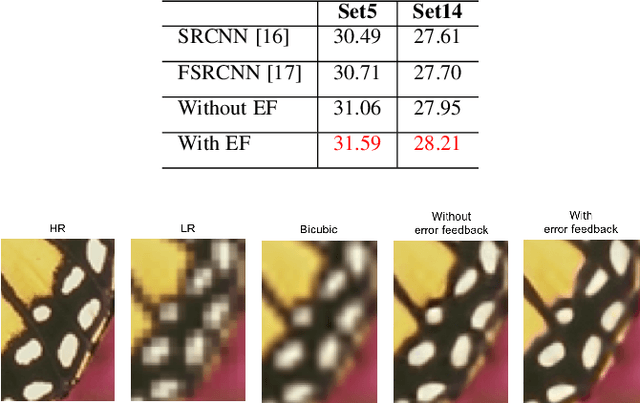
Previous feed-forward architectures of recently proposed deep super-resolution networks learn the features of low-resolution inputs and the non-linear mapping from those to a high-resolution output. However, this approach does not fully address the mutual dependencies of low- and high-resolution images. We propose Deep Back-Projection Networks (DBPN), the winner of two image super-resolution challenges (NTIRE2018 and PIRM2018), that exploit iterative up- and down-sampling layers. These layers are formed as a unit providing an error feedback mechanism for projection errors. We construct mutually-connected up- and down-sampling units each of which represents different types of image degradation and high-resolution components. We also show that extending this idea to several variants applying the latest deep network trends, such as recurrent network, dense connection, and residual learning, to improve the performance. The experimental results yield superior results and in particular establishing new state-of-the-art results across multiple data sets, especially for large scaling factors such as 8x.
Recurrent Back-Projection Network for Video Super-Resolution
Mar 25, 2019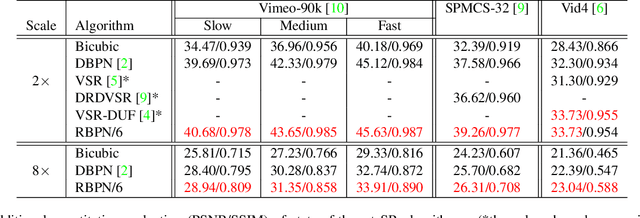



We proposed a novel architecture for the problem of video super-resolution. We integrate spatial and temporal contexts from continuous video frames using a recurrent encoder-decoder module, that fuses multi-frame information with the more traditional, single frame super-resolution path for the target frame. In contrast to most prior work where frames are pooled together by stacking or warping, our model, the Recurrent Back-Projection Network (RBPN) treats each context frame as a separate source of information. These sources are combined in an iterative refinement framework inspired by the idea of back-projection in multiple-image super-resolution. This is aided by explicitly representing estimated inter-frame motion with respect to the target, rather than explicitly aligning frames. We propose a new video super-resolution benchmark, allowing evaluation at a larger scale and considering videos in different motion regimes. Experimental results demonstrate that our RBPN is superior to existing methods on several datasets.
Task-Driven Super Resolution: Object Detection in Low-resolution Images
Mar 30, 2018



We consider how image super resolution (SR) can contribute to an object detection task in low-resolution images. Intuitively, SR gives a positive impact on the object detection task. While several previous works demonstrated that this intuition is correct, SR and detector are optimized independently in these works. This paper proposes a novel framework to train a deep neural network where the SR sub-network explicitly incorporates a detection loss in its training objective, via a tradeoff with a traditional detection loss. This end-to-end training procedure allows us to train SR preprocessing for any differentiable detector. We demonstrate that our task-driven SR consistently and significantly improves accuracy of an object detector on low-resolution images for a variety of conditions and scaling factors.
Deep Back-Projection Networks For Super-Resolution
Mar 07, 2018
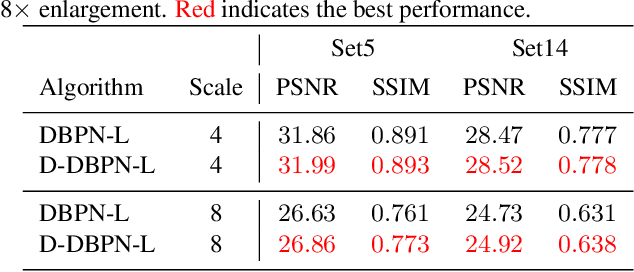
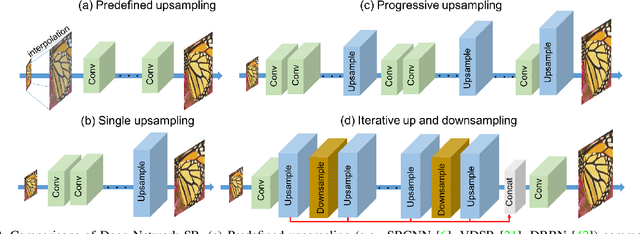
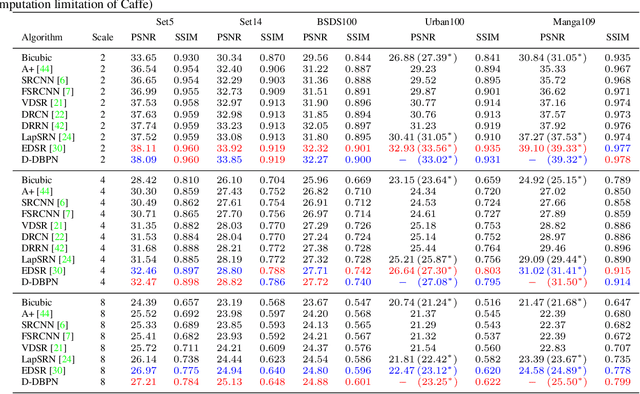
The feed-forward architectures of recently proposed deep super-resolution networks learn representations of low-resolution inputs, and the non-linear mapping from those to high-resolution output. However, this approach does not fully address the mutual dependencies of low- and high-resolution images. We propose Deep Back-Projection Networks (DBPN), that exploit iterative up- and down-sampling layers, providing an error feedback mechanism for projection errors at each stage. We construct mutually-connected up- and down-sampling stages each of which represents different types of image degradation and high-resolution components. We show that extending this idea to allow concatenation of features across up- and down-sampling stages (Dense DBPN) allows us to reconstruct further improve super-resolution, yielding superior results and in particular establishing new state of the art results for large scaling factors such as 8x across multiple data sets.