 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Digitalization of Bioassays in the Open Research Knowledge Graph
Mar 28, 2022


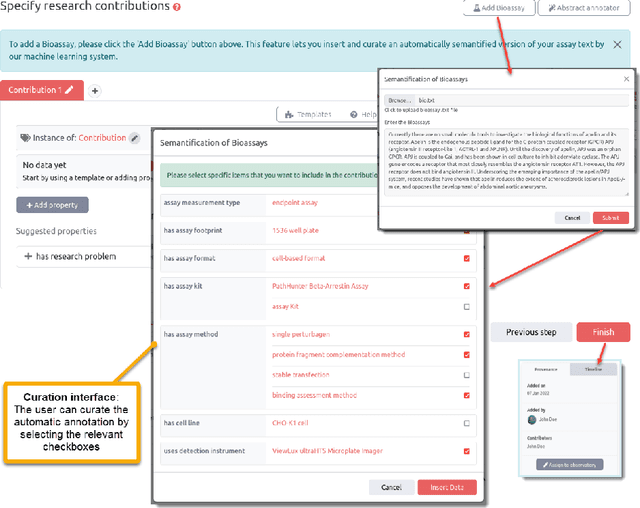
Background: Recent years are seeing a growing impetus in the semantification of scholarly knowledge at the fine-grained level of scientific entities in knowledge graphs. The Open Research Knowledge Graph (ORKG) https://www.orkg.org/ represents an important step in this direction, with thousands of scholarly contributions as structured, fine-grained, machine-readable data. There is a need, however, to engender change in traditional community practices of recording contributions as unstructured, non-machine-readable text. For this in turn, there is a strong need for AI tools designed for scientists that permit easy and accurate semantification of their scholarly contributions. We present one such tool, ORKG-assays. Implementation: ORKG-assays is a freely available AI micro-service in ORKG written in Python designed to assist scientists obtain semantified bioassays as a set of triples. It uses an AI-based clustering algorithm which on gold-standard evaluations over 900 bioassays with 5,514 unique property-value pairs for 103 predicates shows competitive performance. Results and Discussion: As a result, semantified assay collections can be surveyed on the ORKG platform via tabulation or chart-based visualizations of key property values of the chemicals and compounds offering smart knowledge access to biochemists and pharmaceutical researchers in the advancement of drug development.
Easy Semantification of Bioassays
Dec 02, 2021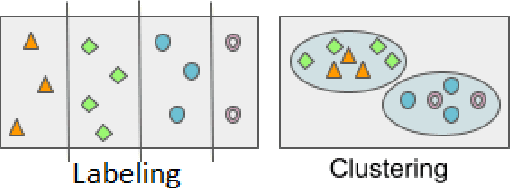


Biological data and knowledge bases increasingly rely on Semantic Web technologies and the use of knowledge graphs for data integration, retrieval and federated queries. We propose a solution for automatically semantifying biological assays. Our solution contrasts the problem of automated semantification as labeling versus clustering where the two methods are on opposite ends of the method complexity spectrum. Characteristically modeling our problem, we find the clustering solution significantly outperforms a deep neural network state-of-the-art labeling approach. This novel contribution is based on two factors: 1) a learning objective closely modeled after the data outperforms an alternative approach with sophisticated semantic modeling; 2) automatically semantifying biological assays achieves a high performance F1 of nearly 83%, which to our knowledge is the first reported standardized evaluation of the task offering a strong benchmark model.
SciBERT-based Semantification of Bioassays in the Open Research Knowledge Graph
Sep 16, 2020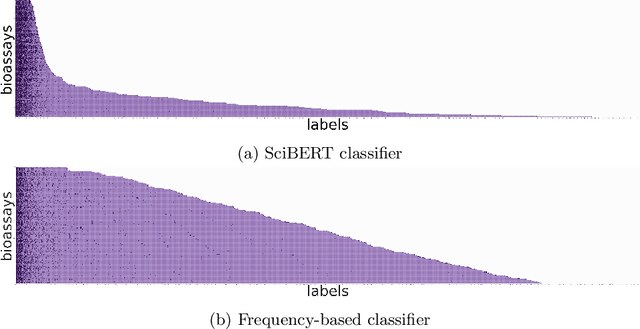

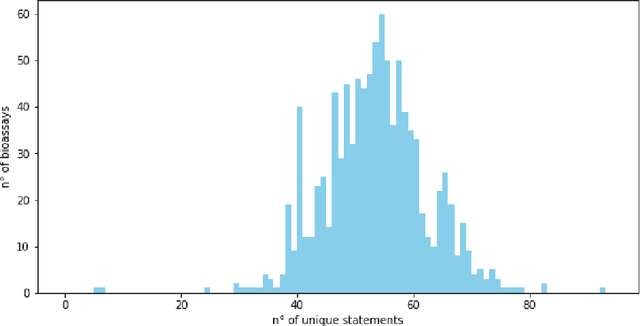
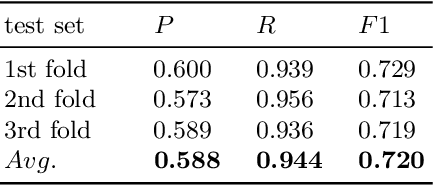
As a novel contribution to the problem of semantifying biological assays, in this paper, we propose a neural-network-based approach to automatically semantify, thereby structure, unstructured bioassay text descriptions. Experimental evaluations, to this end, show promise as the neural-based semantification significantly outperforms a naive frequency-based baseline approach. Specifically, the neural method attains 72% F1 versus 47% F1 from the frequency-based method.