 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernelized Back-Projection Networks for Blind Super Resolution
Feb 17, 2023



Since non-blind Super Resolution (SR) fails to super-resolve Low-Resolution (LR) images degraded by arbitrary degradations, SR with the degradation model is required. However, this paper reveals that non-blind SR that is trained simply with various blur kernels exhibits comparable performance as those with the degradation model for blind SR. This result motivates us to revisit high-performance non-blind SR and extend it to blind SR with blur kernels. This paper proposes two SR networks by integrating kernel estimation and SR branches in an iterative end-to-end manner. In the first model, which is called the Kernel Conditioned Back-Projection Network (KCBPN), the low-dimensional kernel representations are estimated for conditioning the SR branch. In our second model, the Kernelized BackProjection Network (KBPN), a raw kernel is estimated and directly employed for modeling the image degradation. The estimated kernel is employed not only for back-propagating its residual but also for forward-propagating the residual to iterative stages. This forward-propagation encourages these stages to learn a variety of different features in different stages by focusing on pixels with large residuals in each stage. Experimental results validate the effectiveness of our proposed networks for kernel estimation and SR. We will release the code for this work.
Image Super-Resolution using Explicit Perceptual Loss
Sep 01, 2020
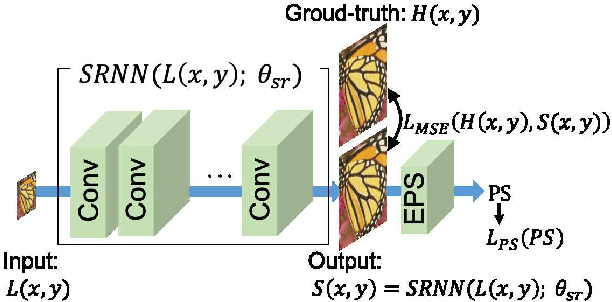

This paper proposes an explicit way to optimize the super-resolution network for generating visually pleasing images. The previous approaches use several loss functions which is hard to interpret and has the implicit relationships to improve the perceptual score. We show how to exploit the machine learning based model which is directly trained to provide the perceptual score on generated images. It is believed that these models can be used to optimizes the super-resolution network which is easier to interpret. We further analyze the characteristic of the existing loss and our proposed explicit perceptual loss for better interpretation. The experimental results show the explicit approach has a higher perceptual score than other approaches. Finally, we demonstrate the relation of explicit perceptual loss and visually pleasing images using subjective evaluation.
Distance Metric Learning for Graph Structured Data
Feb 03, 2020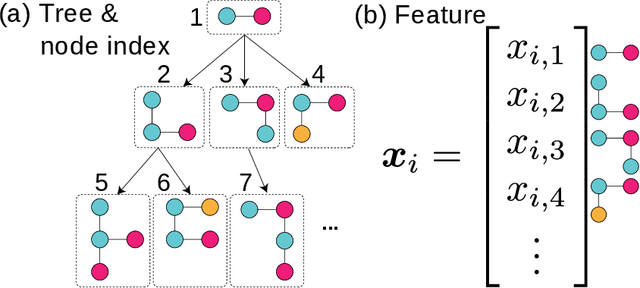



Graphs are versatile tools for representing structured data. Therefore, a variety of machine learning methods have been studied for graph data analysis. Although many of those learning methods depend on the measurement of differences between input graphs, defining an appropriate distance metric for a graph remains a controversial issue. Hence, we propose a supervised distance metric learning method for the graph classification problem. Our method, named interpretable graph metric learning (IGML), learns discriminative metrics in a subgraph-based feature space, which has a strong graph representation capability. By introducing a sparsity-inducing penalty on a weight of each subgraph, IGML can identify a small number of important subgraphs that can provide insight about the given classification task. Since our formulation has a large number of optimization variables, an efficient algorithm is also proposed by using pruning techniques based on safe screening and working set selection methods. An important property of IGML is that the optimality of the solution is guaranteed because the problem is formulated as a convex problem and our pruning strategies only discard unnecessary subgraphs. Further, we show that IGML is also applicable to other structured data such as item-set and sequence data, and that it can incorporate vertex-label similarity by using a transportation-based subgraph feature. We empirically evaluate the computational efficiency and classification performance on several benchmark datasets and show some illustrative examples demonstrating that IGML identifies important subgraphs from a given graph dataset.
Safe Triplet Screening for Distance Metric Learning
Oct 05, 2018
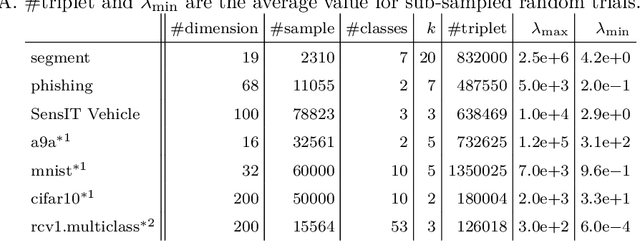


We study safe screening for metric learning. Distance metric learning can optimize a metric over a set of triplets, each one of which is defined by a pair of same class instances and an instance in a different class. However, the number of possible triplets is quite huge even for a small dataset. Our safe triplet screening identifies triplets which can be safely removed from the optimization problem without losing the optimality. Compared with existing safe screening studies, triplet screening is particularly significant because of (1) the huge number of possible triplets, and (2) the semi-definite constraint in the optimization. We derive several variants of screening rules, and analyze their relationships. Numerical experiments on benchmark datasets demonstrate the effectiveness of safe triplet screening.