 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance Metric Learning for Graph Structured Data
Paper and Code
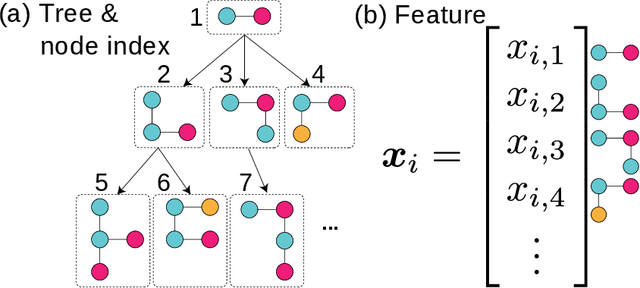



Graphs are versatile tools for representing structured data. Therefore, a variety of machine learning methods have been studied for graph data analysis. Although many of those learning methods depend on the measurement of differences between input graphs, defining an appropriate distance metric for a graph remains a controversial issue. Hence, we propose a supervised distance metric learning method for the graph classification problem. Our method, named interpretable graph metric learning (IGML), learns discriminative metrics in a subgraph-based feature space, which has a strong graph representation capability. By introducing a sparsity-inducing penalty on a weight of each subgraph, IGML can identify a small number of important subgraphs that can provide insight about the given classification task. Since our formulation has a large number of optimization variables, an efficient algorithm is also proposed by using pruning techniques based on safe screening and working set selection methods. An important property of IGML is that the optimality of the solution is guaranteed because the problem is formulated as a convex problem and our pruning strategies only discard unnecessary subgraphs. Further, we show that IGML is also applicable to other structured data such as item-set and sequence data, and that it can incorporate vertex-label similarity by using a transportation-based subgraph feature. We empirically evaluate the computational efficiency and classification performance on several benchmark datasets and show some illustrative examples demonstrating that IGML identifies important subgraphs from a given graph dataset.