 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Conformal Prediction to Distribution Shifts Without Labels
Paper and Code
Jun 03, 2024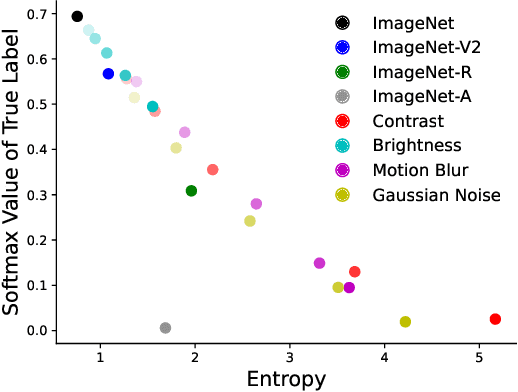
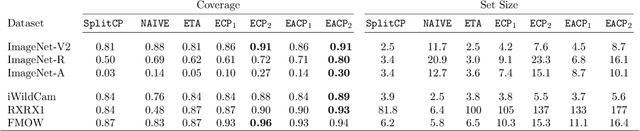
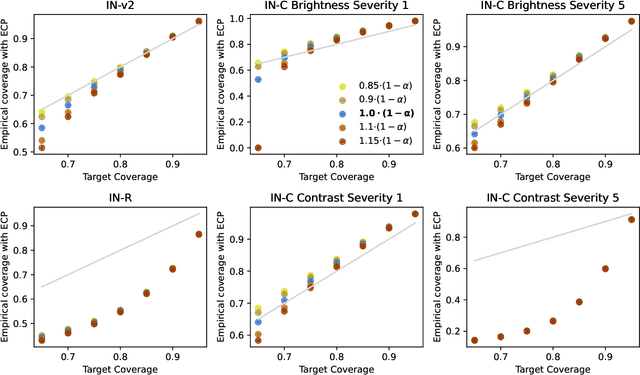

Conformal prediction (CP) enables machine learning models to output prediction sets with guaranteed coverage rate, assuming exchangeable data. Unfortunately, the exchangeability assumption is frequently violated due to distribution shifts in practice, and the challenge is often compounded by the lack of ground truth labels at test time. Focusing on classification in this paper, our goal is to improve the quality of CP-generated prediction sets using only unlabeled data from the test domain. This is achieved by two new methods called ECP and EACP, that adjust the score function in CP according to the base model's uncertainty on the unlabeled test data. Through extensive experiments on a number of large-scale datasets and neural network architectures, we show that our methods provide consistent improvement over existing baselines and nearly match the performance of supervised algorithms.