 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end multi-modal product matching in fashion e-commerce
Mar 18, 2024

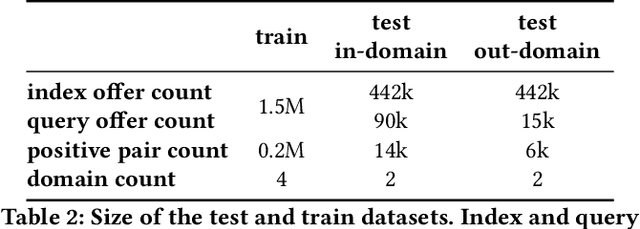

Product matching, the task of identifying different representations of the same product for better discoverability, curation, and pricing, is a key capability for online marketplace and e-commerce companies. We present a robust multi-modal product matching system in an industry setting, where large datasets, data distribution shifts and unseen domains pose challenges. We compare different approaches and conclude that a relatively straightforward projection of pretrained image and text encoders, trained through contrastive learning, yields state-of-the-art results, while balancing cost and performance. Our solution outperforms single modality matching systems and large pretrained models, such as CLIP. Furthermore we show how a human-in-the-loop process can be combined with model-based predictions to achieve near perfect precision in a production system.
Self-Supervised and Semi-Supervised Polyp Segmentation using Synthetic Data
Jul 22, 2023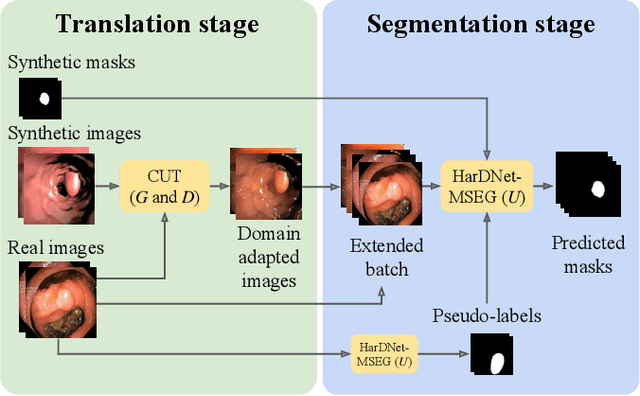
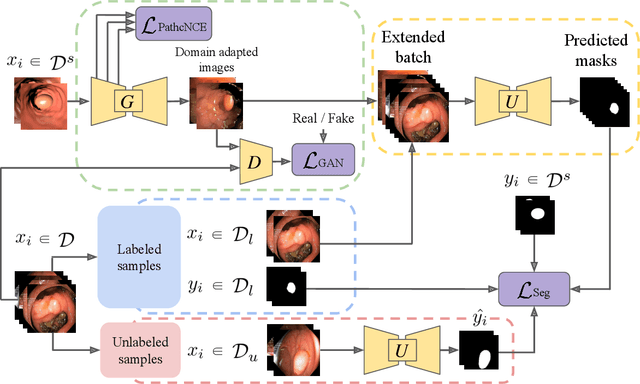
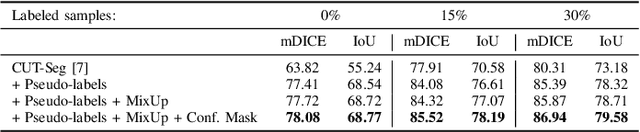
Early detection of colorectal polyps is of utmost importance for their treatment and for colorectal cancer prevention. Computer vision techniques have the potential to aid professionals in the diagnosis stage, where colonoscopies are manually carried out to examine the entirety of the patient's colon. The main challenge in medical imaging is the lack of data, and a further challenge specific to polyp segmentation approaches is the difficulty of manually labeling the available data: the annotation process for segmentation tasks is very time-consuming. While most recent approaches address the data availability challenge with sophisticated techniques to better exploit the available labeled data, few of them explore the self-supervised or semi-supervised paradigm, where the amount of labeling required is greatly reduced. To address both challenges, we leverage synthetic data and propose an end-to-end model for polyp segmentation that integrates real and synthetic data to artificially increase the size of the datasets and aid the training when unlabeled samples are available. Concretely, our model, Pl-CUT-Seg, transforms synthetic images with an image-to-image translation module and combines the resulting images with real images to train a segmentation model, where we use model predictions as pseudo-labels to better leverage unlabeled samples. Additionally, we propose PL-CUT-Seg+, an improved version of the model that incorporates targeted regularization to address the domain gap between real and synthetic images. The models are evaluated on standard benchmarks for polyp segmentation and reach state-of-the-art results in the self- and semi-supervised setups.
Joint one-sided synthetic unpaired image translation and segmentation for colorectal cancer prevention
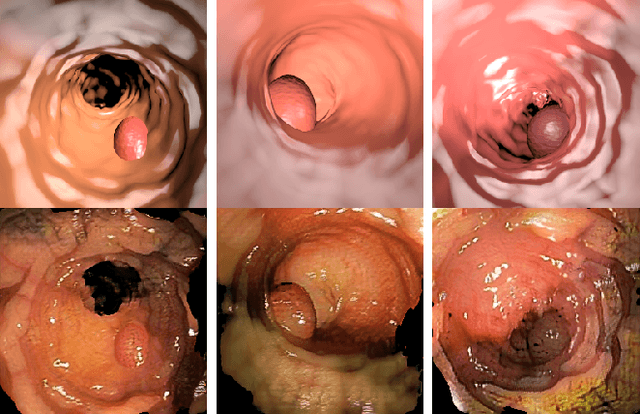
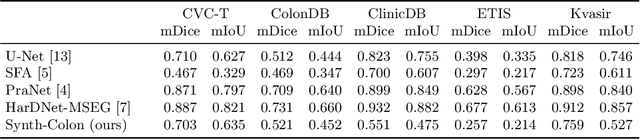
Jul 20, 2023Deep learning has shown excellent performance in analysing medical images. However, datasets are difficult to obtain due privacy issues, standardization problems, and lack of annotations. We address these problems by producing realistic synthetic images using a combination of 3D technologies and generative adversarial networks. We propose CUT-seg, a joint training where a segmentation model and a generative model are jointly trained to produce realistic images while learning to segment polyps. We take advantage of recent one-sided translation models because they use significantly less memory, allowing us to add a segmentation model in the training loop. CUT-seg performs better, is computationally less expensive, and requires less real images than other memory-intensive image translation approaches that require two stage training. Promising results are achieved on five real polyp segmentation datasets using only one real image and zero real annotations. As a part of this study we release Synth-Colon, an entirely synthetic dataset that includes 20000 realistic colon images and additional details about depth and 3D geometry: https://enric1994.github.io/synth-colon
Fashion CUT: Unsupervised domain adaptation for visual pattern classification in clothes using synthetic data and pseudo-labels
May 09, 2023Accurate product information is critical for e-commerce stores to allow customers to browse, filter, and search for products. Product data quality is affected by missing or incorrect information resulting in poor customer experience. While machine learning can be used to correct inaccurate or missing information, achieving high performance on fashion image classification tasks requires large amounts of annotated data, but it is expensive to generate due to labeling costs. One solution can be to generate synthetic data which requires no manual labeling. However, training a model with a dataset of solely synthetic images can lead to poor generalization when performing inference on real-world data because of the domain shift. We introduce a new unsupervised domain adaptation technique that converts images from the synthetic domain into the real-world domain. Our approach combines a generative neural network and a classifier that are jointly trained to produce realistic images while preserving the synthetic label information. We found that using real-world pseudo-labels during training helps the classifier to generalize in the real-world domain, reducing the synthetic bias. We successfully train a visual pattern classification model in the fashion domain without real-world annotations. Experiments show that our method outperforms other unsupervised domain adaptation algorithms.
Synthetic data for unsupervised polyp segmentation
Feb 17, 2022

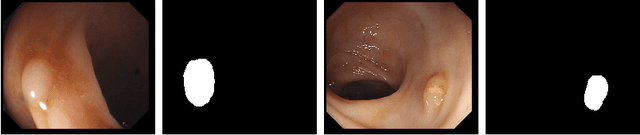
Deep learning has shown excellent performance in analysing medical images. However, datasets are difficult to obtain due privacy issues, standardization problems, and lack of annotations. We address these problems by producing realistic synthetic images using a combination of 3D technologies and generative adversarial networks. We use zero annotations from medical professionals in our pipeline. Our fully unsupervised method achieves promising results on five real polyp segmentation datasets. As a part of this study we release Synth-Colon, an entirely synthetic dataset that includes 20000 realistic colon images and additional details about depth and 3D geometry: https://enric1994.github.io/synth-colon
Domain Randomization for Object Counting
Feb 17, 2022
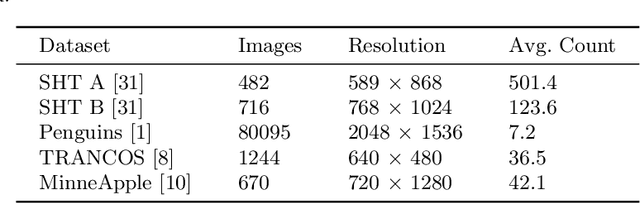


Recently, the use of synthetic datasets based on game engines has been shown to improve the performance of several tasks in computer vision. However, these datasets are typically only appropriate for the specific domains depicted in computer games, such as urban scenes involving vehicles and people. In this paper, we present an approach to generate synthetic datasets for object counting for any domain without the need for photo-realistic techniques manually generated by expensive teams of 3D artists. We introduce a domain randomization approach for object counting based on synthetic datasets that are quick and inexpensive to generate. We deliberately avoid photorealism and drastically increase the variability of the dataset, producing images with random textures and 3D transformations, which improves generalization. Experiments show that our method facilitates good performance on various real word object counting datasets for multiple domains: people, vehicles, penguins, and fruit. The source code is available at: https://github.com/enric1994/dr4oc