 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end multi-modal product matching in fashion e-commerce
Mar 18, 2024

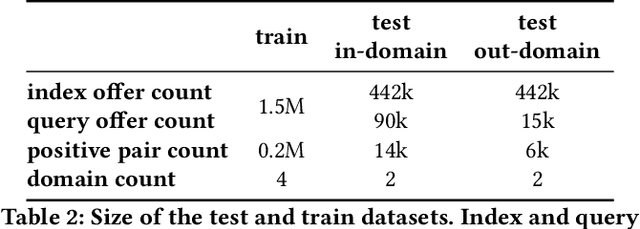

Product matching, the task of identifying different representations of the same product for better discoverability, curation, and pricing, is a key capability for online marketplace and e-commerce companies. We present a robust multi-modal product matching system in an industry setting, where large datasets, data distribution shifts and unseen domains pose challenges. We compare different approaches and conclude that a relatively straightforward projection of pretrained image and text encoders, trained through contrastive learning, yields state-of-the-art results, while balancing cost and performance. Our solution outperforms single modality matching systems and large pretrained models, such as CLIP. Furthermore we show how a human-in-the-loop process can be combined with model-based predictions to achieve near perfect precision in a production system.
Realistic Zero-Shot Cross-Lingual Transfer in Legal Topic Classification
Jun 08, 2022
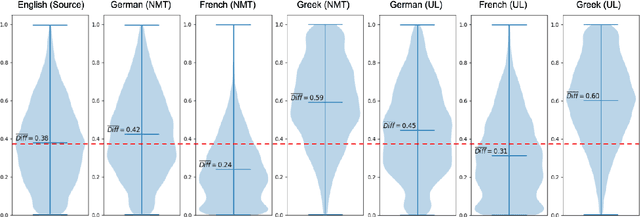
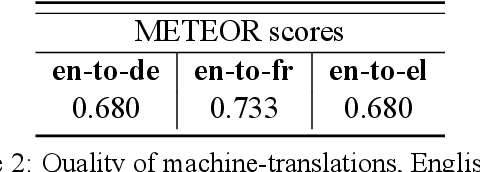
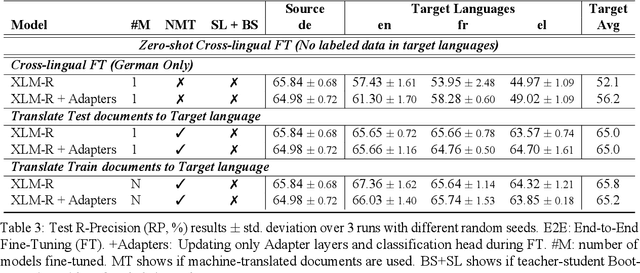
We consider zero-shot cross-lingual transfer in legal topic classification using the recent MultiEURLEX dataset. Since the original dataset contains parallel documents, which is unrealistic for zero-shot cross-lingual transfer, we develop a new version of the dataset without parallel documents. We use it to show that translation-based methods vastly outperform cross-lingual fine-tuning of multilingually pre-trained models, the best previous zero-shot transfer method for MultiEURLEX. We also develop a bilingual teacher-student zero-shot transfer approach, which exploits additional unlabeled documents of the target language and performs better than a model fine-tuned directly on labeled target language documents.