 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end multi-modal product matching in fashion e-commerce
Mar 18, 2024

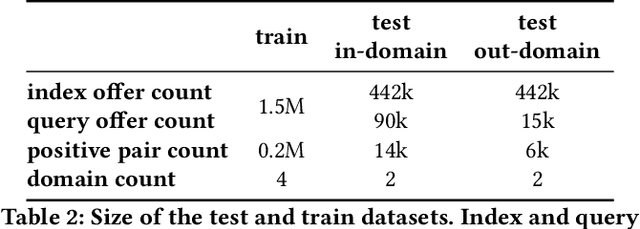

Product matching, the task of identifying different representations of the same product for better discoverability, curation, and pricing, is a key capability for online marketplace and e-commerce companies. We present a robust multi-modal product matching system in an industry setting, where large datasets, data distribution shifts and unseen domains pose challenges. We compare different approaches and conclude that a relatively straightforward projection of pretrained image and text encoders, trained through contrastive learning, yields state-of-the-art results, while balancing cost and performance. Our solution outperforms single modality matching systems and large pretrained models, such as CLIP. Furthermore we show how a human-in-the-loop process can be combined with model-based predictions to achieve near perfect precision in a production system.
MatKB: Semantic Search for Polycrystalline Materials Synthesis Procedures
Feb 11, 2023In this paper, we present a novel approach to knowledge extraction and retrieval using Natural Language Processing (NLP) techniques for material science. Our goal is to automatically mine structured knowledge from millions of research articles in the field of polycrystalline materials and make it easily accessible to the broader community. The proposed method leverages NLP techniques such as entity recognition and document classification to extract relevant information and build an extensive knowledge base, from a collection of 9.5 Million publications. The resulting knowledge base is integrated into a search engine, which enables users to search for information about specific materials, properties, and experiments with greater precision than traditional search engines like Google. We hope our results can enable material scientists quickly locate desired experimental procedures, compare their differences, and even inspire them to design new experiments. Our website will be available at Github \footnote{https://github.com/Xianjun-Yang/PcMSP.git} soon.