 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end multi-modal product matching in fashion e-commerce
Mar 18, 2024

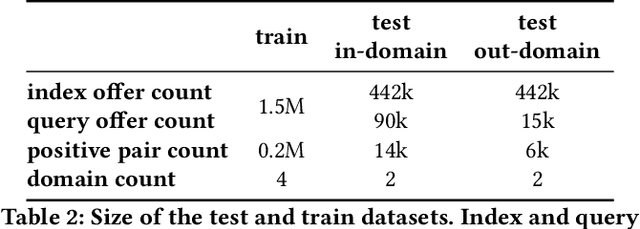

Product matching, the task of identifying different representations of the same product for better discoverability, curation, and pricing, is a key capability for online marketplace and e-commerce companies. We present a robust multi-modal product matching system in an industry setting, where large datasets, data distribution shifts and unseen domains pose challenges. We compare different approaches and conclude that a relatively straightforward projection of pretrained image and text encoders, trained through contrastive learning, yields state-of-the-art results, while balancing cost and performance. Our solution outperforms single modality matching systems and large pretrained models, such as CLIP. Furthermore we show how a human-in-the-loop process can be combined with model-based predictions to achieve near perfect precision in a production system.
Constitutional Precedent of Amicus Briefs
Jul 07, 2016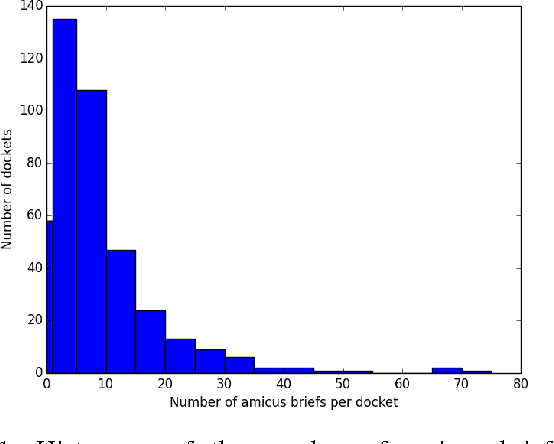
We investigate shared language between U.S. Supreme Court majority opinions and interest groups' corresponding amicus briefs. Specifically, we evaluate whether language that originated in an amicus brief acquired legal precedent status by being cited in the Court's opinion. Using plagiarism detection software, automated querying of a large legal database, and manual analysis, we establish seven instances where interest group amici were able to formulate constitutional case law, setting binding legal precedent. We discuss several such instances for their implications in the Supreme Court's creation of case law.
Angrier Birds: Bayesian reinforcement learning
Jan 07, 2016


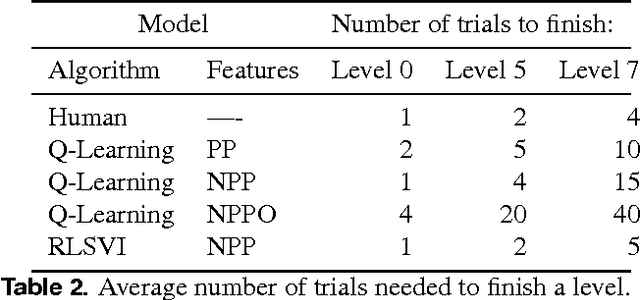
We train a reinforcement learner to play a simplified version of the game Angry Birds. The learner is provided with a game state in a manner similar to the output that could be produced by computer vision algorithms. We improve on the efficiency of regular {\epsilon}-greedy Q-Learning with linear function approximation through more systematic exploration in Randomized Least Squares Value Iteration (RLSVI), an algorithm that samples its policy from a posterior distribution on optimal policies. With larger state-action spaces, efficient exploration becomes increasingly important, as evidenced by the faster learning in RLSVI.