Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAngrier Birds: Bayesian reinforcement learning
Jan 07, 2016


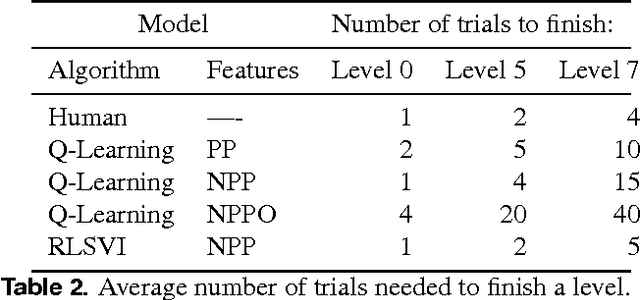
We train a reinforcement learner to play a simplified version of the game Angry Birds. The learner is provided with a game state in a manner similar to the output that could be produced by computer vision algorithms. We improve on the efficiency of regular {\epsilon}-greedy Q-Learning with linear function approximation through more systematic exploration in Randomized Least Squares Value Iteration (RLSVI), an algorithm that samples its policy from a posterior distribution on optimal policies. With larger state-action spaces, efficient exploration becomes increasingly important, as evidenced by the faster learning in RLSVI.
* Stanford University CS221 Final Project
Via