 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReclaiming Residual Knowledge: A Novel Paradigm to Low-Bit Quantization
Aug 01, 2024This paper explores a novel paradigm in low-bit (i.e. 4-bits or lower) quantization, differing from existing state-of-the-art methods, by framing optimal quantization as an architecture search problem within convolutional neural networks (ConvNets). Our framework, dubbed \textbf{CoRa} (Optimal Quantization Residual \textbf{Co}nvolutional Operator Low-\textbf{Ra}nk Adaptation), is motivated by two key aspects. Firstly, quantization residual knowledge, i.e. the lost information between floating-point weights and quantized weights, has long been neglected by the research community. Reclaiming the critical residual knowledge, with an infinitesimal extra parameter cost, can reverse performance degradation without training. Secondly, state-of-the-art quantization frameworks search for optimal quantized weights to address the performance degradation. Yet, the vast search spaces in weight optimization pose a challenge for the efficient optimization in large models. For example, state-of-the-art BRECQ necessitates $2 \times 10^4$ iterations to quantize models. Fundamentally differing from existing methods, \textbf{CoRa} searches for the optimal architectures of low-rank adapters, reclaiming critical quantization residual knowledge, within the search spaces smaller compared to the weight spaces, by many orders of magnitude. The low-rank adapters approximate the quantization residual weights, discarded in previous methods. We evaluate our approach over multiple pre-trained ConvNets on ImageNet. \textbf{CoRa} achieves comparable performance against both state-of-the-art quantization-aware training and post-training quantization baselines, in $4$-bit and $3$-bit quantization, by using less than $250$ iterations on a small calibration set with $1600$ images. Thus, \textbf{CoRa} establishes a new state-of-the-art in terms of the optimization efficiency in low-bit quantization.
Video Anomaly Detection via Spatio-Temporal Pseudo-Anomaly Generation : A Unified Approach
Nov 27, 2023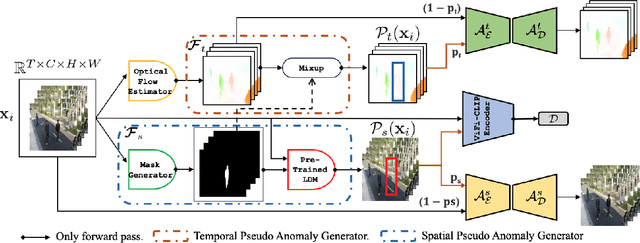
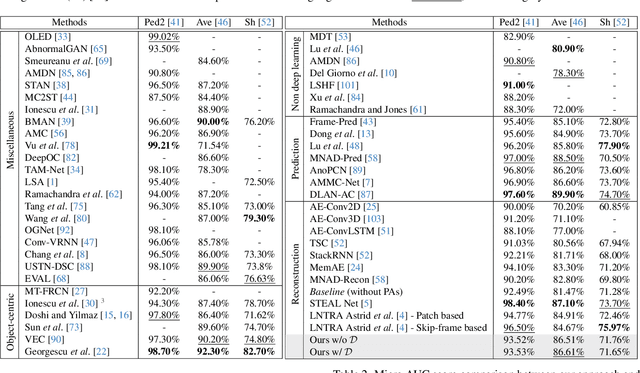


Video Anomaly Detection (VAD) is an open-set recognition task, which is usually formulated as a one-class classification (OCC) problem, where training data is comprised of videos with normal instances while test data contains both normal and anomalous instances. Recent works have investigated the creation of pseudo-anomalies (PAs) using only the normal data and making strong assumptions about real-world anomalies with regards to abnormality of objects and speed of motion to inject prior information about anomalies in an autoencoder (AE) based reconstruction model during training. This work proposes a novel method for generating generic spatio-temporal PAs by inpainting a masked out region of an image using a pre-trained Latent Diffusion Model and further perturbing the optical flow using mixup to emulate spatio-temporal distortions in the data. In addition, we present a simple unified framework to detect real-world anomalies under the OCC setting by learning three types of anomaly indicators, namely reconstruction quality, temporal irregularity and semantic inconsistency. Extensive experiments on four VAD benchmark datasets namely Ped2, Avenue, ShanghaiTech and UBnormal demonstrate that our method performs on par with other existing state-of-the-art PAs generation and reconstruction based methods under the OCC setting. Our analysis also examines the transferability and generalisation of PAs across these datasets, offering valuable insights by identifying real-world anomalies through PAs.
Unifying Synergies between Self-supervised Learning and Dynamic Computation
Jan 22, 2023



Self-supervised learning (SSL) approaches have made major strides forward by emulating the performance of their supervised counterparts on several computer vision benchmarks. This, however, comes at a cost of substantially larger model sizes, and computationally expensive training strategies, which eventually lead to larger inference times making it impractical for resource constrained industrial settings. Techniques like knowledge distillation (KD), dynamic computation (DC), and pruning are often used to obtain a lightweight sub-network, which usually involves multiple epochs of fine-tuning of a large pre-trained model, making it more computationally challenging. In this work we propose a novel perspective on the interplay between SSL and DC paradigms that can be leveraged to simultaneously learn a dense and gated (sparse/lightweight) sub-network from scratch offering a good accuracy-efficiency trade-off, and therefore yielding a generic and multi-purpose architecture for application specific industrial settings. Our study overall conveys a constructive message: exhaustive experiments on several image classification benchmarks: CIFAR-10, STL-10, CIFAR-100, and ImageNet-100, demonstrates that the proposed training strategy provides a dense and corresponding sparse sub-network that achieves comparable (on-par) performance compared with the vanilla self-supervised setting, but at a significant reduction in computation in terms of FLOPs under a range of target budgets.
Efficient CNN Implementation for Eye-Gaze Estimation on Low-Power/Low-Quality Consumer Imaging Systems
Jun 28, 2018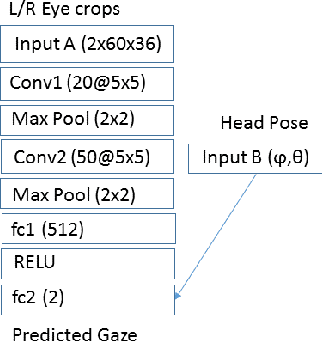
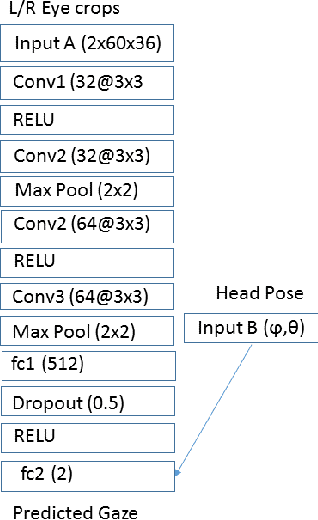
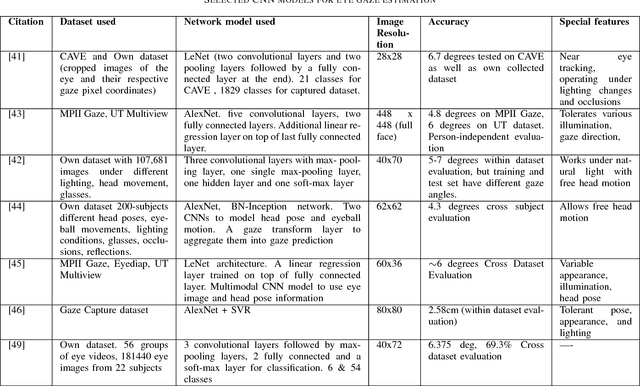
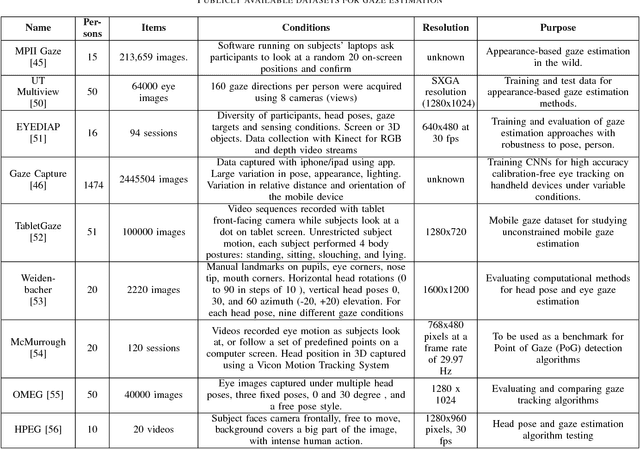
Accurate and efficient eye gaze estimation is important for emerging consumer electronic systems such as driver monitoring systems and novel user interfaces. Such systems are required to operate reliably in difficult, unconstrained environments with low power consumption and at minimal cost. In this paper a new hardware friendly, convolutional neural network model with minimal computational requirements is introduced and assessed for efficient appearance-based gaze estimation. The model is tested and compared against existing appearance based CNN approaches, achieving better eye gaze accuracy with significantly fewer computational requirements. A brief updated literature review is also provided.