 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastSal: a Computationally Efficient Network for Visual Saliency Prediction
Paper and Code
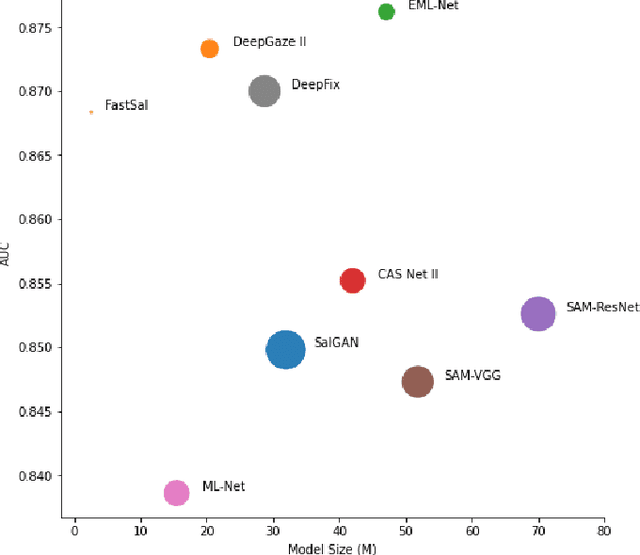
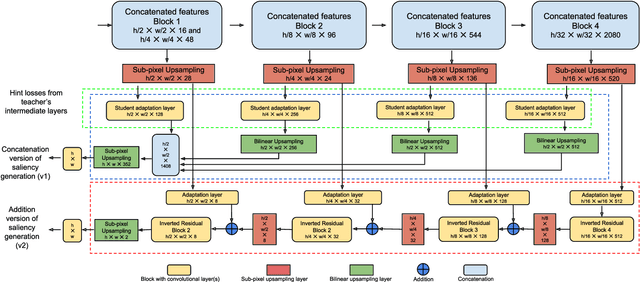
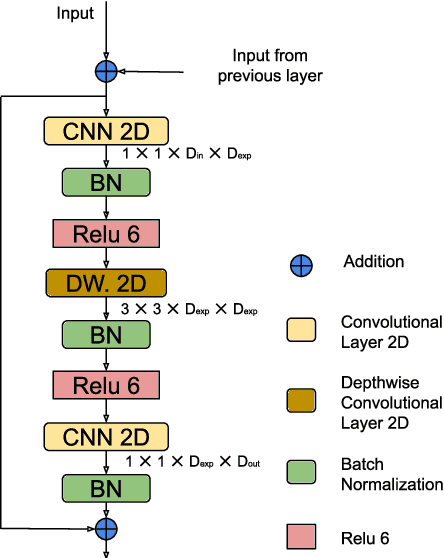
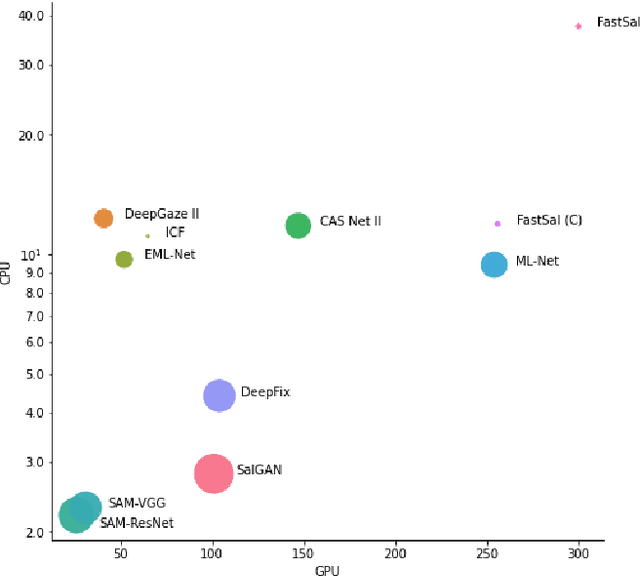
This paper focuses on the problem of visual saliency prediction, predicting regions of an image that tend to attract human visual attention, under a constrained computational budget. We modify and test various recent efficient convolutional neural network architectures like EfficientNet and MobileNetV2 and compare them with existing state-of-the-art saliency models such as SalGAN and DeepGaze II both in terms of standard accuracy metrics like AUC and NSS, and in terms of the computational complexity and model size. We find that MobileNetV2 makes an excellent backbone for a visual saliency model and can be effective even without a complex decoder. We also show that knowledge transfer from a more computationally expensive model like DeepGaze II can be achieved via pseudo-labelling an unlabelled dataset, and that this approach gives result on-par with many state-of-the-art algorithms with a fraction of the computational cost and model size. Source code is available at https://github.com/feiyanhu/FastSal.