 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Saliency Detection with Domain Adaptation using Hierarchical Gradient Reversal Layers
Paper and Code
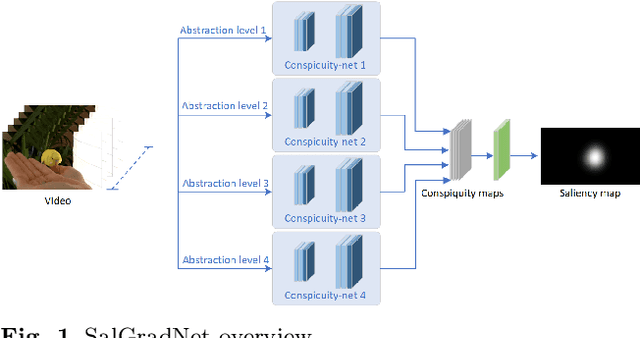
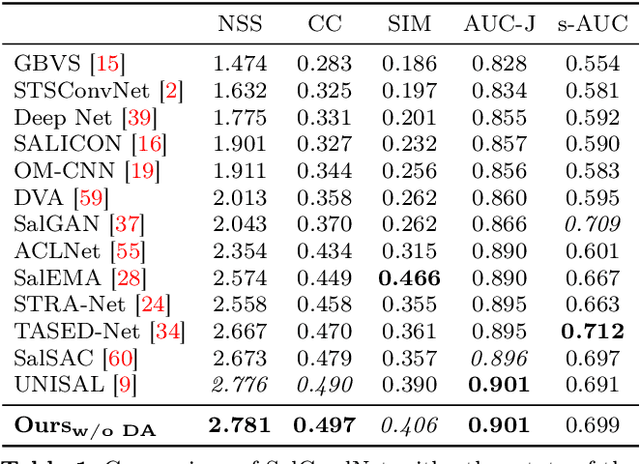

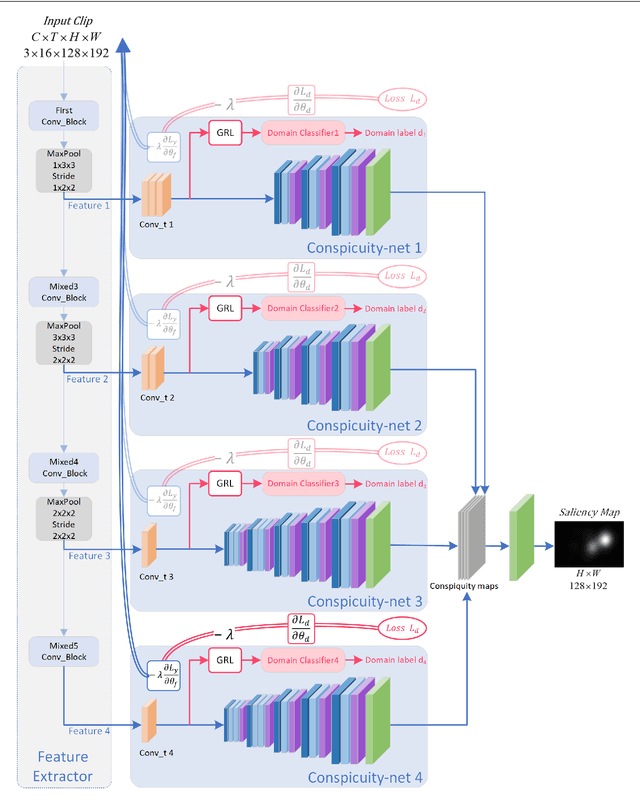
In this work, we propose a 3D fully convolutional architecture for video saliency detection that employs multi-head supervision on intermediate maps (referred to as conspicuity maps) generated using features extracted at different abstraction level. More specifically, the model employs a single encoder and features extracted at different levels are then passed to multiple decoders aiming at predicting multiple saliency instances that are finally combined to obtain final output saliency maps. We also combine the hierarchical features extracted from the model's encoder with a domain adaptation approach based on gradient reversal at multiple scales in order to improve the generalization capabilities on datasets for which no annotations are provided during training. The results of our experiments on standard benchmarks, namely DHF1K, Hollywood2 and UCF Sports, show that the proposed model outperforms state-of-the-art methods on most metrics for supervised saliency prediction. Moreover, when tested in an unsupervised settings, it is able to obtain performance comparable to those achieved by supervised state-of-the-art methods.