 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Categorical Archive of ChatGPT Failures
Paper and Code
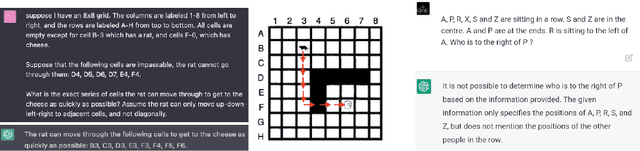
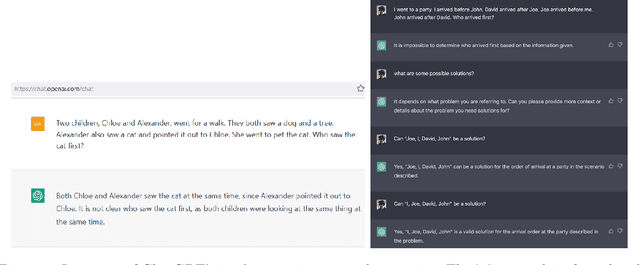
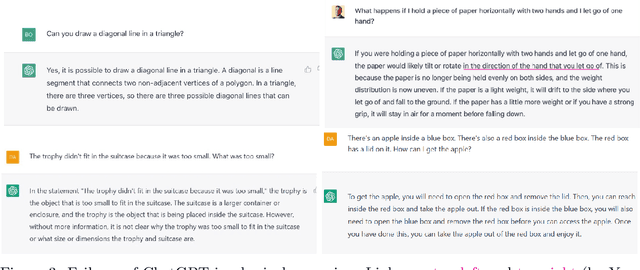
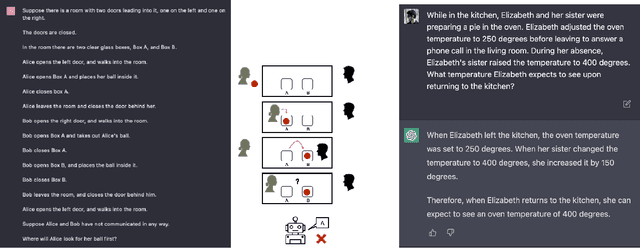
Large language models have been demonstrated to be valuable in different fields. ChatGPT, developed by OpenAI, has been trained using massive amounts of data and simulates human conversation by comprehending context and generating appropriate responses. It has garnered significant attention due to its ability to effectively answer a broad range of human inquiries, with fluent and comprehensive answers surpassing prior public chatbots in both security and usefulness. However, a comprehensive analysis of ChatGPT's failures is lacking, which is the focus of this study. Eleven categories of failures, including reasoning, factual errors, math, coding, and bias, are presented and discussed. The risks, limitations, and societal implications of ChatGPT are also highlighted. The goal of this study is to assist researchers and developers in enhancing future language models and chatbots.