 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Audio-visual Synchronization for Active Speaker Detection
Paper and Code

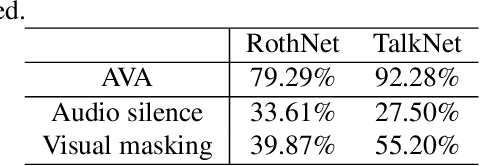

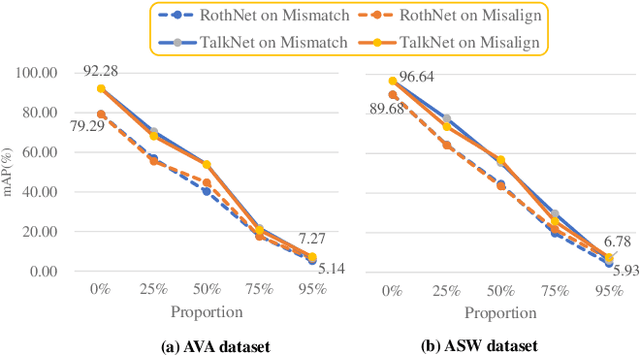
Active speaker detection (ASD) systems are important modules for analyzing multi-talker conversations. They aim to detect which speakers or none are talking in a visual scene at any given time. Existing research on ASD does not agree on the definition of active speakers. We clarify the definition in this work and require synchronization between the audio and visual speaking activities. This clarification of definition is motivated by our extensive experiments, through which we discover that existing ASD methods fail in modeling the audio-visual synchronization and often classify unsynchronized videos as active speaking. To address this problem, we propose a cross-modal contrastive learning strategy and apply positional encoding in attention modules for supervised ASD models to leverage the synchronization cue. Experimental results suggest that our model can successfully detect unsynchronized speaking as not speaking, addressing the limitation of current models.