 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbGraph: Conflict-Aware Evidence Arbitration for Reliable Long-Form Retrieval-Augmented Generation
Apr 20, 2026Retrieval-augmented generation (RAG) remains unreliable in long-form settings, where retrieved evidence is noisy or contradictory, making it difficult for RAG pipelines to maintain factual consistency. Existing approaches focus on retrieval expansion or verification during generation, leaving conflict resolution entangled with generation. To address this limitation, we propose ArbGraph, a framework for pre-generation evidence arbitration in long-form RAG that explicitly resolves factual conflicts. ArbGraph decomposes retrieved documents into atomic claims and organizes them into a conflict-aware evidence graph with explicit support and contradiction relations. On top of this graph, we introduce an intensity-driven iterative arbitration mechanism that propagates credibility signals through evidence interactions, enabling the system to suppress unreliable and inconsistent claims before final generation. In this way, ArbGraph separates evidence validation from text generation and provides a coherent evidence foundation for downstream long-form generation. We evaluate ArbGraph on two widely used long-form RAG benchmarks, LongFact and RAGChecker, using multiple large language model backbones. Experimental results show that ArbGraph consistently improves factual recall and information density while reducing hallucinations and sensitivity to retrieval noise. Additional analyses show that these gains are evident under conflicting or ambiguous evidence, highlighting the effectiveness of evidence-level conflict resolution for improving the reliability of long-form RAG. The implementation is publicly available at https://github.com/1212Judy/ArbGraph.
Emulating Clinician Cognition via Self-Evolving Deep Clinical Research
Mar 11, 2026Clinical diagnosis is a complex cognitive process, grounded in dynamic cue acquisition and continuous expertise accumulation. Yet most current artificial intelligence (AI) systems are misaligned with this reality, treating diagnosis as single-pass retrospective prediction while lacking auditable mechanisms for governed improvement. We developed DxEvolve, a self-evolving diagnostic agent that bridges these gaps through an interactive deep clinical research workflow. The framework autonomously requisitions examinations and continually externalizes clinical experience from increasing encounter exposure as diagnostic cognition primitives. On the MIMIC-CDM benchmark, DxEvolve improved diagnostic accuracy by 11.2% on average over backbone models and reached 90.4% on a reader-study subset, comparable to the clinician reference (88.8%). DxEvolve improved accuracy on an independent external cohort by 10.2% (categories covered by the source cohort) and 17.1% (uncovered categories) compared to the competitive method. By transforming experience into a governable learning asset, DxEvolve supports an accountable pathway for the continual evolution of clinical AI.
STARec: An Efficient Agent Framework for Recommender Systems via Autonomous Deliberate Reasoning
Aug 26, 2025While modern recommender systems are instrumental in navigating information abundance, they remain fundamentally limited by static user modeling and reactive decision-making paradigms. Current large language model (LLM)-based agents inherit these shortcomings through their overreliance on heuristic pattern matching, yielding recommendations prone to shallow correlation bias, limited causal inference, and brittleness in sparse-data scenarios. We introduce STARec, a slow-thinking augmented agent framework that endows recommender systems with autonomous deliberative reasoning capabilities. Each user is modeled as an agent with parallel cognitions: fast response for immediate interactions and slow reasoning that performs chain-of-thought rationales. To cultivate intrinsic slow thinking, we develop anchored reinforcement training - a two-stage paradigm combining structured knowledge distillation from advanced reasoning models with preference-aligned reward shaping. This hybrid approach scaffolds agents in acquiring foundational capabilities (preference summarization, rationale generation) while enabling dynamic policy adaptation through simulated feedback loops. Experiments on MovieLens 1M and Amazon CDs benchmarks demonstrate that STARec achieves substantial performance gains compared with state-of-the-art baselines, despite using only 0.4% of the full training data.
BEE-RAG: Balanced Entropy Engineering for Retrieval-Augmented Generation
Aug 07, 2025



With the rapid advancement of large language models (LLMs), retrieval-augmented generation (RAG) has emerged as a critical approach to supplement the inherent knowledge limitations of LLMs. However, due to the typically large volume of retrieved information, RAG tends to operate with long context lengths. From the perspective of entropy engineering, we identify unconstrained entropy growth and attention dilution due to long retrieval context as significant factors affecting RAG performance. In this paper, we propose the balanced entropy-engineered RAG (BEE-RAG) framework, which improves the adaptability of RAG systems to varying context lengths through the principle of entropy invariance. By leveraging balanced context entropy to reformulate attention dynamics, BEE-RAG separates attention sensitivity from context length, ensuring a stable entropy level. Building upon this, we introduce a zero-shot inference strategy for multi-importance estimation and a parameter-efficient adaptive fine-tuning mechanism to obtain the optimal balancing factor for different settings. Extensive experiments across multiple RAG tasks demonstrate the effectiveness of BEE-RAG.
Reinforced Informativeness Optimization for Long-Form Retrieval-Augmented Generation
May 27, 2025



Long-form question answering (LFQA) presents unique challenges for large language models, requiring the synthesis of coherent, paragraph-length answers. While retrieval-augmented generation (RAG) systems have emerged as a promising solution, existing research struggles with key limitations: the scarcity of high-quality training data for long-form generation, the compounding risk of hallucination in extended outputs, and the absence of reliable evaluation metrics for factual completeness. In this paper, we propose RioRAG, a novel reinforcement learning (RL) framework that advances long-form RAG through reinforced informativeness optimization. Our approach introduces two fundamental innovations to address the core challenges. First, we develop an RL training paradigm of reinforced informativeness optimization that directly optimizes informativeness and effectively addresses the slow-thinking deficit in conventional RAG systems, bypassing the need for expensive supervised data. Second, we propose a nugget-centric hierarchical reward modeling approach that enables precise assessment of long-form answers through a three-stage process: extracting the nugget from every source webpage, constructing a nugget claim checklist, and computing rewards based on factual alignment. Extensive experiments on two LFQA benchmarks LongFact and RAGChecker demonstrate the effectiveness of the proposed method. Our codes are available at https://github.com/RUCAIBox/RioRAG.
SimpleDeepSearcher: Deep Information Seeking via Web-Powered Reasoning Trajectory Synthesis
May 22, 2025



Retrieval-augmented generation (RAG) systems have advanced large language models (LLMs) in complex deep search scenarios requiring multi-step reasoning and iterative information retrieval. However, existing approaches face critical limitations that lack high-quality training trajectories or suffer from the distributional mismatches in simulated environments and prohibitive computational costs for real-world deployment. This paper introduces SimpleDeepSearcher, a lightweight yet effective framework that bridges this gap through strategic data engineering rather than complex training paradigms. Our approach synthesizes high-quality training data by simulating realistic user interactions in live web search environments, coupled with a multi-criteria curation strategy that optimizes the diversity and quality of input and output side. Experiments on five benchmarks across diverse domains demonstrate that SFT on only 871 curated samples yields significant improvements over RL-based baselines. Our work establishes SFT as a viable pathway by systematically addressing the data-scarce bottleneck, offering practical insights for efficient deep search systems. Our code is available at https://github.com/RUCAIBox/SimpleDeepSearcher.
Unveiling Knowledge Utilization Mechanisms in LLM-based Retrieval-Augmented Generation
May 17, 2025
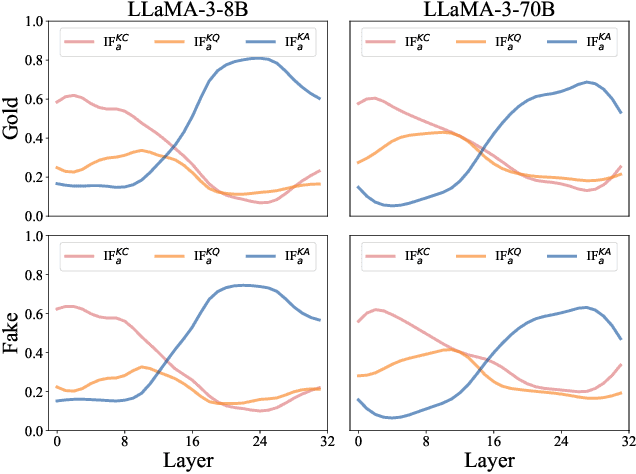
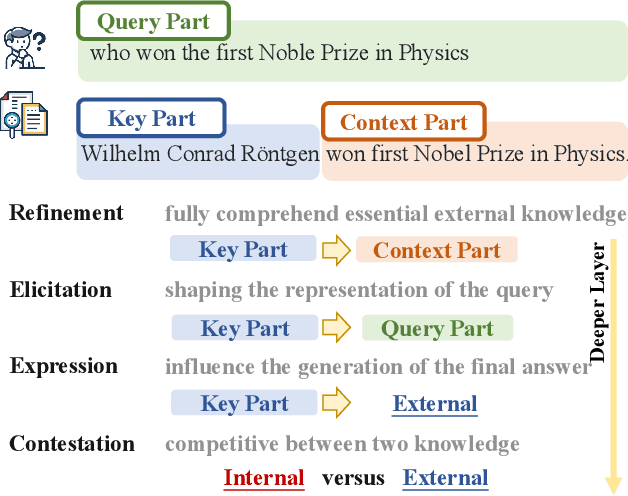
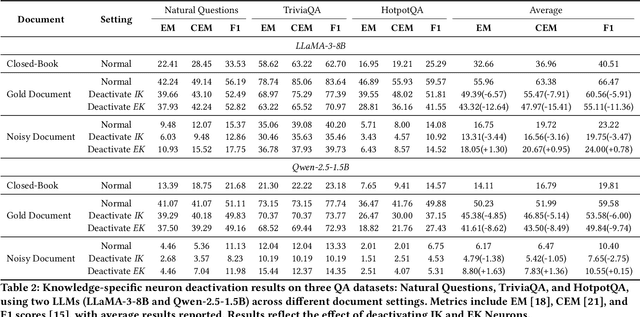
Considering the inherent limitations of parametric knowledge in large language models (LLMs), retrieval-augmented generation (RAG) is widely employed to expand their knowledge scope. Since RAG has shown promise in knowledge-intensive tasks like open-domain question answering, its broader application to complex tasks and intelligent assistants has further advanced its utility. Despite this progress, the underlying knowledge utilization mechanisms of LLM-based RAG remain underexplored. In this paper, we present a systematic investigation of the intrinsic mechanisms by which LLMs integrate internal (parametric) and external (retrieved) knowledge in RAG scenarios. Specially, we employ knowledge stream analysis at the macroscopic level, and investigate the function of individual modules at the microscopic level. Drawing on knowledge streaming analyses, we decompose the knowledge utilization process into four distinct stages within LLM layers: knowledge refinement, knowledge elicitation, knowledge expression, and knowledge contestation. We further demonstrate that the relevance of passages guides the streaming of knowledge through these stages. At the module level, we introduce a new method, knowledge activation probability entropy (KAPE) for neuron identification associated with either internal or external knowledge. By selectively deactivating these neurons, we achieve targeted shifts in the LLM's reliance on one knowledge source over the other. Moreover, we discern complementary roles for multi-head attention and multi-layer perceptron layers during knowledge formation. These insights offer a foundation for improving interpretability and reliability in retrieval-augmented LLMs, paving the way for more robust and transparent generative solutions in knowledge-intensive domains.
Holistically Guided Monte Carlo Tree Search for Intricate Information Seeking
Feb 07, 2025



In the era of vast digital information, the sheer volume and heterogeneity of available information present significant challenges for intricate information seeking. Users frequently face multistep web search tasks that involve navigating vast and varied data sources. This complexity demands every step remains comprehensive, accurate, and relevant. However, traditional search methods often struggle to balance the need for localized precision with the broader context required for holistic understanding, leaving critical facets of intricate queries underexplored. In this paper, we introduce an LLM-based search assistant that adopts a new information seeking paradigm with holistically guided Monte Carlo tree search (HG-MCTS). We reformulate the task as a progressive information collection process with a knowledge memory and unite an adaptive checklist with multi-perspective reward modeling in MCTS. The adaptive checklist provides explicit sub-goals to guide the MCTS process toward comprehensive coverage of complex user queries. Simultaneously, our multi-perspective reward modeling offers both exploration and retrieval rewards, along with progress feedback that tracks completed and remaining sub-goals, refining the checklist as the tree search progresses. By striking a balance between localized tree expansion and global guidance, HG-MCTS reduces redundancy in search paths and ensures that all crucial aspects of an intricate query are properly addressed. Extensive experiments on real-world intricate information seeking tasks demonstrate that HG-MCTS acquires thorough knowledge collections and delivers more accurate final responses compared with existing baselines.
RAG-Star: Enhancing Deliberative Reasoning with Retrieval Augmented Verification and Refinement
Dec 17, 2024



Existing large language models (LLMs) show exceptional problem-solving capabilities but might struggle with complex reasoning tasks. Despite the successes of chain-of-thought and tree-based search methods, they mainly depend on the internal knowledge of LLMs to search over intermediate reasoning steps, limited to dealing with simple tasks involving fewer reasoning steps. In this paper, we propose \textbf{RAG-Star}, a novel RAG approach that integrates the retrieved information to guide the tree-based deliberative reasoning process that relies on the inherent knowledge of LLMs. By leveraging Monte Carlo Tree Search, RAG-Star iteratively plans intermediate sub-queries and answers for reasoning based on the LLM itself. To consolidate internal and external knowledge, we propose an retrieval-augmented verification that utilizes query- and answer-aware reward modeling to provide feedback for the inherent reasoning of LLMs. Our experiments involving Llama-3.1-8B-Instruct and GPT-4o demonstrate that RAG-Star significantly outperforms previous RAG and reasoning methods.
Self-Calibrated Listwise Reranking with Large Language Models
Nov 07, 2024
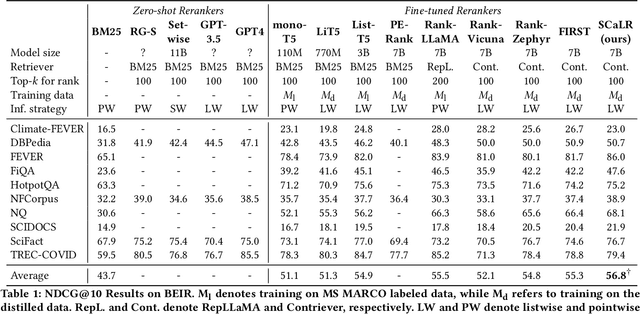
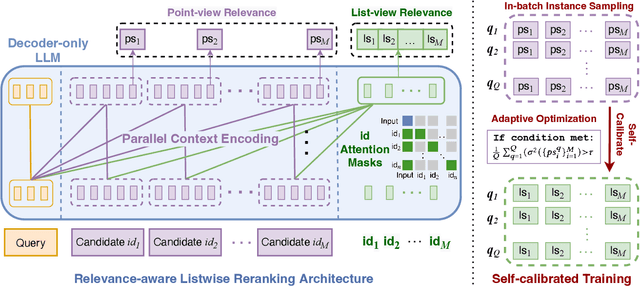

Large language models (LLMs), with advanced linguistic capabilities, have been employed in reranking tasks through a sequence-to-sequence approach. In this paradigm, multiple passages are reranked in a listwise manner and a textual reranked permutation is generated. However, due to the limited context window of LLMs, this reranking paradigm requires a sliding window strategy to iteratively handle larger candidate sets. This not only increases computational costs but also restricts the LLM from fully capturing all the comparison information for all candidates. To address these challenges, we propose a novel self-calibrated listwise reranking method, which aims to leverage LLMs to produce global relevance scores for ranking. To achieve it, we first propose the relevance-aware listwise reranking framework, which incorporates explicit list-view relevance scores to improve reranking efficiency and enable global comparison across the entire candidate set. Second, to ensure the comparability of the computed scores, we propose self-calibrated training that uses point-view relevance assessments generated internally by the LLM itself to calibrate the list-view relevance assessments. Extensive experiments and comprehensive analysis on the BEIR benchmark and TREC Deep Learning Tracks demonstrate the effectiveness and efficiency of our proposed method.