 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DBench: A Scalable 3D Benchmark and Instruction-Tuning Dataset
Paper and Code
Apr 23, 2024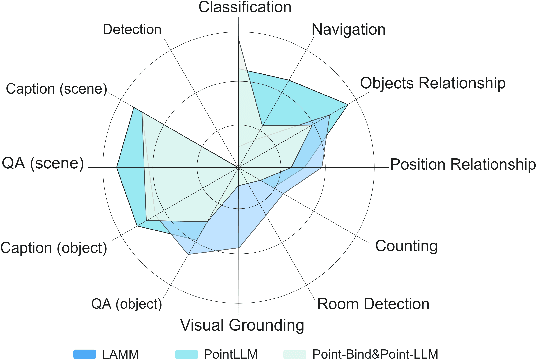
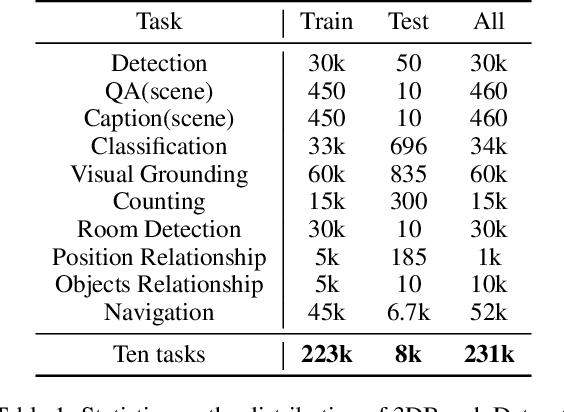
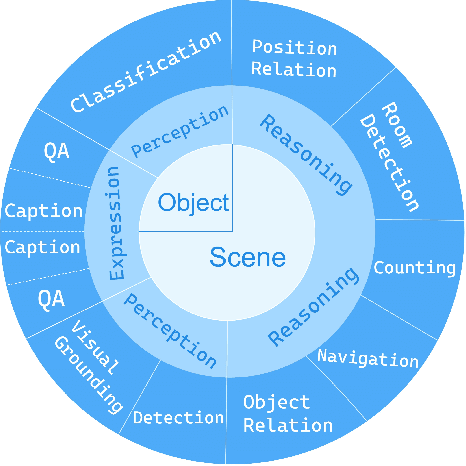

Evaluating the performance of Multi-modal Large Language Models (MLLMs), integrating both point cloud and language, presents significant challenges. The lack of a comprehensive assessment hampers determining whether these models truly represent advancements, thereby impeding further progress in the field. Current evaluations heavily rely on classification and caption tasks, falling short in providing a thorough assessment of MLLMs. A pressing need exists for a more sophisticated evaluation method capable of thoroughly analyzing the spatial understanding and expressive capabilities of these models. To address these issues, we introduce a scalable 3D benchmark, accompanied by a large-scale instruction-tuning dataset known as 3DBench, providing an extensible platform for a comprehensive evaluation of MLLMs. Specifically, we establish the benchmark that spans a wide range of spatial and semantic scales, from object-level to scene-level, addressing both perception and planning tasks. Furthermore, we present a rigorous pipeline for automatically constructing scalable 3D instruction-tuning datasets, covering 10 diverse multi-modal tasks with more than 0.23 million QA pairs generated in total. Thorough experiments evaluating trending MLLMs, comparisons against existing datasets, and variations of training protocols demonstrate the superiority of 3DBench, offering valuable insights into current limitations and potential research directions.