 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting a comparability mapping to improve bi-lingual data categorization: a three-mode data analysis perspective
Feb 26, 2015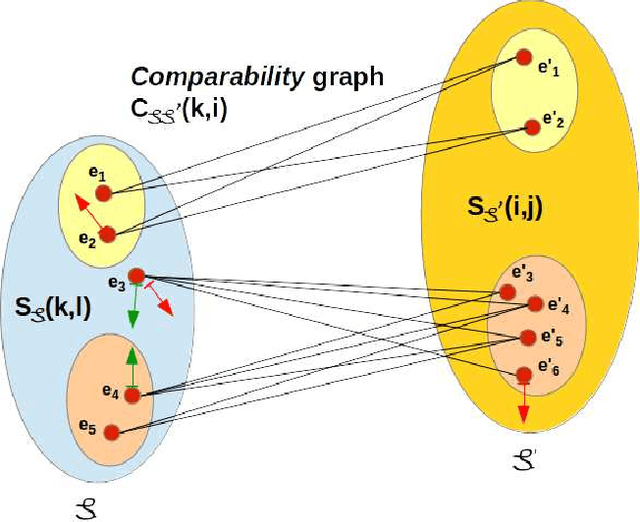
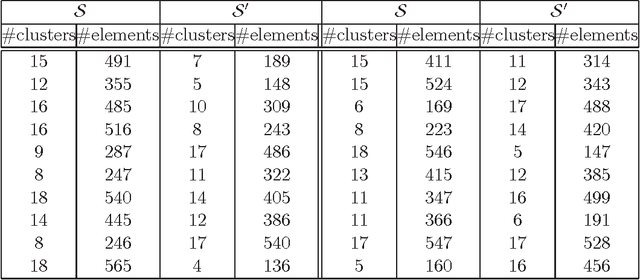
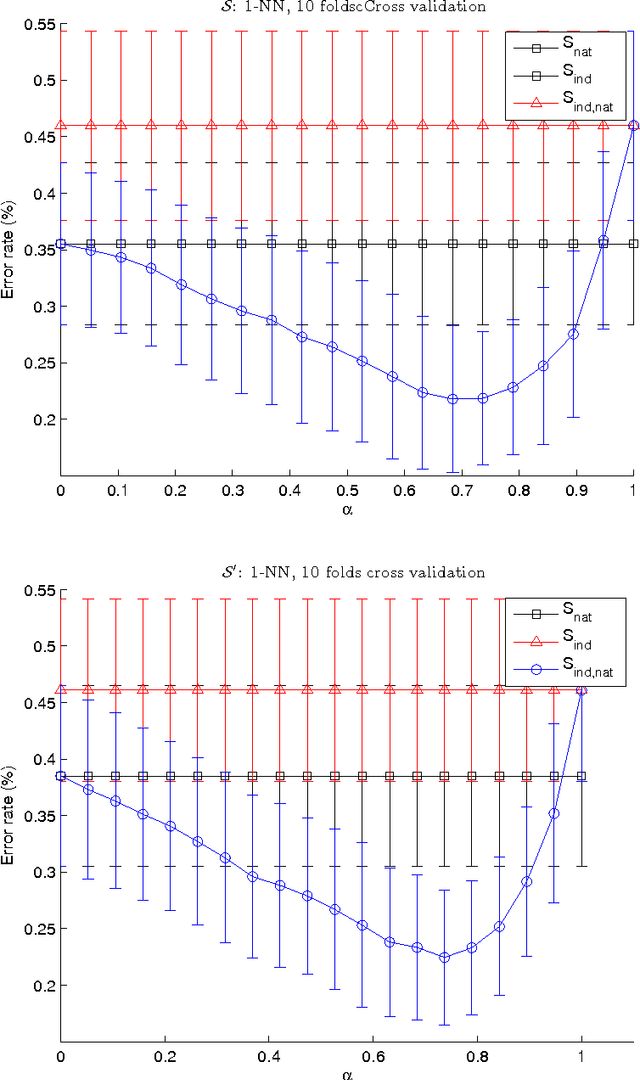
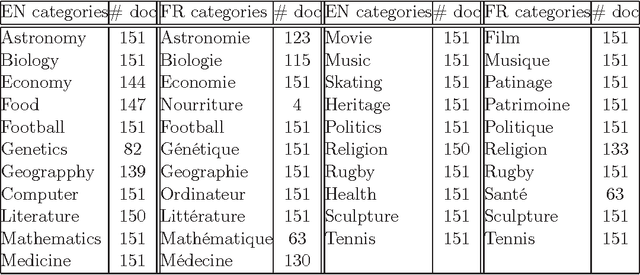
We address in this paper the co-clustering and co-classification of bilingual data laying in two linguistic similarity spaces when a comparability measure defining a mapping between these two spaces is available. A new approach that we can characterized as a three-mode analysis scheme, is proposed to mix the comparability measure with the two similarity measures. Our aim is to improve jointly the accuracy of classification and clustering tasks performed in each of the two linguistic spaces, as well as the quality of the final alignment of comparable clusters that can be obtained. We used first some purely synthetic random data sets to assess our formal similarity-comparability mixing model. We then propose two variants of the comparability measure that has been defined by (Li and Gaussier 2010) in the context of bilingual lexicon extraction to adapt it to clustering or categorizing tasks. These two variant measures are subsequently used to evaluate our similarity-comparability mixing model in the context of the co-classification and co-clustering of comparable textual data sets collected from Wikipedia categories for the English and French languages. Our experiments show clear improvements in clustering and classification accuracies when mixing comparability with similarity measures, with, as expected, a higher robustness obtained when the two comparability variant measures that we propose are used. We believe that this approach is particularly well suited for the construction of thematic comparable corpora of controllable quality.