 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Timbre Remapping with Differentiable DSP
Jul 05, 2024



Timbre is a primary mode of expression in diverse musical contexts. However, prevalent audio-driven synthesis methods predominantly rely on pitch and loudness envelopes, effectively flattening timbral expression from the input. Our approach draws on the concept of timbre analogies and investigates how timbral expression from an input signal can be mapped onto controls for a synthesizer. Leveraging differentiable digital signal processing, our method facilitates direct optimization of synthesizer parameters through a novel feature difference loss. This loss function, designed to learn relative timbral differences between musical events, prioritizes the subtleties of graded timbre modulations within phrases, allowing for meaningful translations in a timbre space. Using snare drum performances as a case study, where timbral expression is central, we demonstrate real-time timbre remapping from acoustic snare drums to a differentiable synthesizer modeled after the Roland TR-808.
Differentiable Modelling of Percussive Audio with Transient and Spectral Synthesis
Sep 13, 2023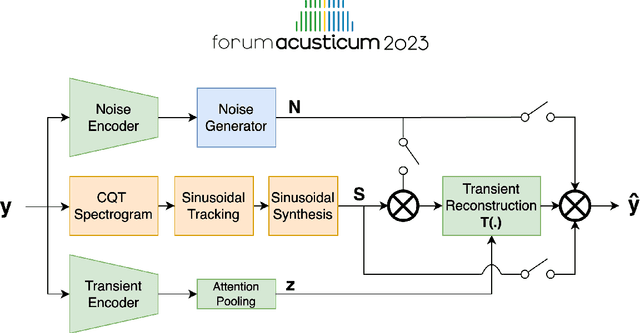
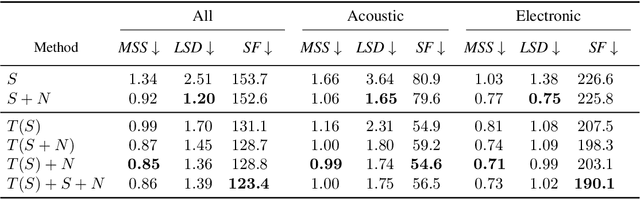
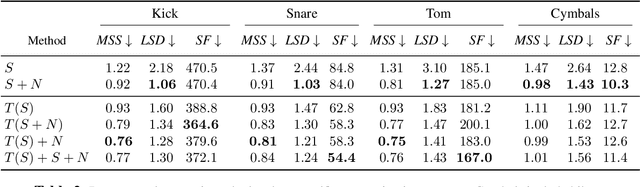
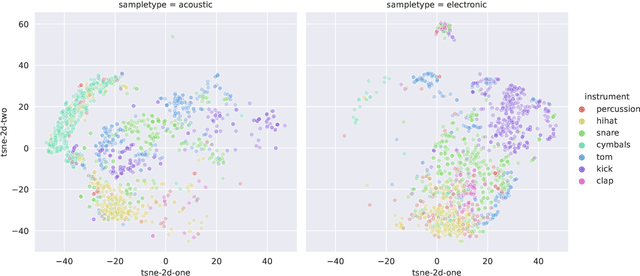
Differentiable digital signal processing (DDSP) techniques, including methods for audio synthesis, have gained attention in recent years and lend themselves to interpretability in the parameter space. However, current differentiable synthesis methods have not explicitly sought to model the transient portion of signals, which is important for percussive sounds. In this work, we present a unified synthesis framework aiming to address transient generation and percussive synthesis within a DDSP framework. To this end, we propose a model for percussive synthesis that builds on sinusoidal modeling synthesis and incorporates a modulated temporal convolutional network for transient generation. We use a modified sinusoidal peak picking algorithm to generate time-varying non-harmonic sinusoids and pair it with differentiable noise and transient encoders that are jointly trained to reconstruct drumset sounds. We compute a set of reconstruction metrics using a large dataset of acoustic and electronic percussion samples that show that our method leads to improved onset signal reconstruction for membranophone percussion instruments.
Conditional Chow-Liu Tree Structures for Modeling Discrete-Valued Vector Time Series
Jul 11, 2012



We consider the problem of modeling discrete-valued vector time series data using extensions of Chow-Liu tree models to capture both dependencies across time and dependencies across variables. Conditional Chow-Liu tree models are introduced, as an extension to standard Chow-Liu trees, for modeling conditional rather than joint densities. We describe learning algorithms for such models and show how they can be used to learn parsimonious representations for the output distributions in hidden Markov models. These models are applied to the important problem of simulating and forecasting daily precipitation occurrence for networks of rain stations. To demonstrate the effectiveness of the models, we compare their performance versus a number of alternatives using historical precipitation data from Southwestern Australia and the Western United States. We illustrate how the structure and parameters of the models can be used to provide an improved meteorological interpretation of such data.