 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Adaptive Reinforcement Learning
Paper and Code
Apr 18, 2020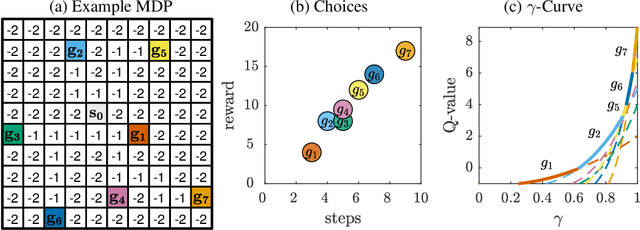
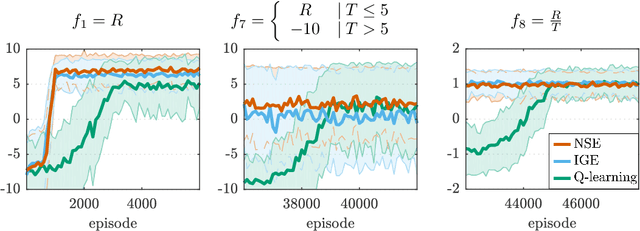
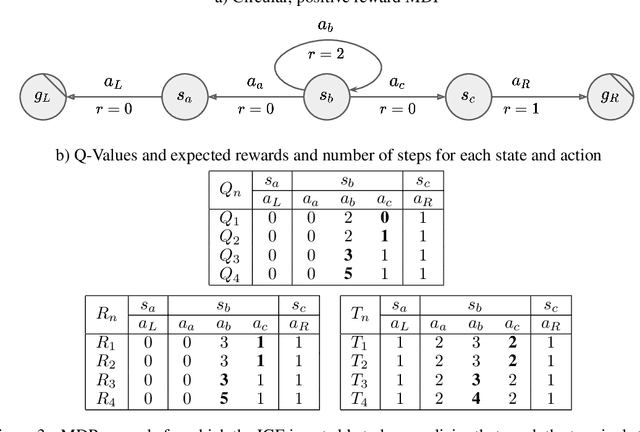
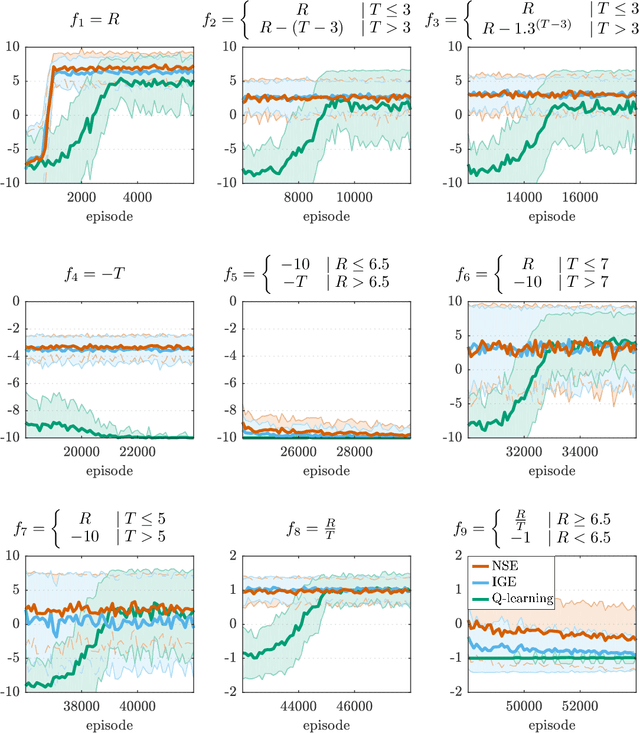
Reinforcement learning (RL) allows to solve complex tasks such as Go often with a stronger performance than humans. However, the learned behaviors are usually fixed to specific tasks and unable to adapt to different contexts. Here we consider the case of adapting RL agents to different time restrictions, such as finishing a task with a given time limit that might change from one task execution to the next. We define such problems as Time Adaptive Markov Decision Processes and introduce two model-free, value-based algorithms: the Independent Gamma-Ensemble and the n-Step Ensemble. In difference to classical approaches, they allow a zero-shot adaptation between different time restrictions. The proposed approaches represent general mechanisms to handle time adaptive tasks making them compatible with many existing RL methods, algorithms, and scenarios.