 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedestrian Trajectory Prediction via Spatial Interaction Transformer Network
Paper and Code
Dec 13, 2021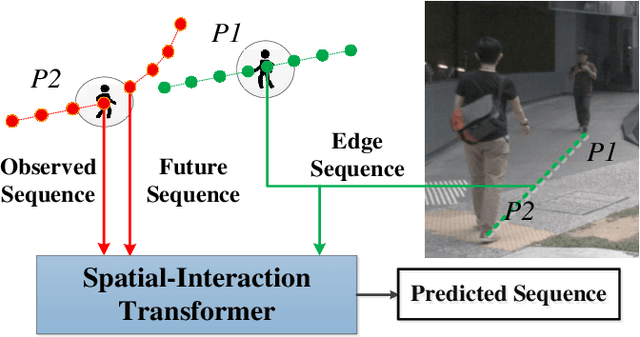
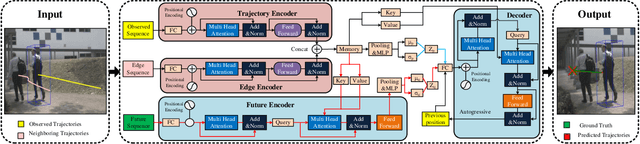
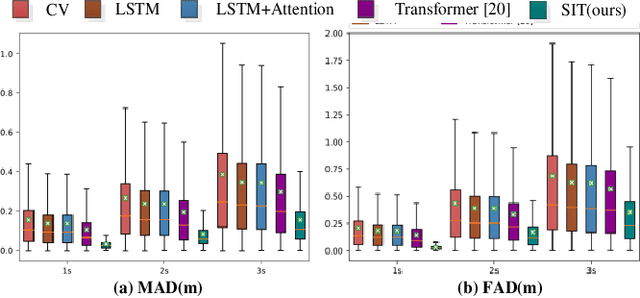
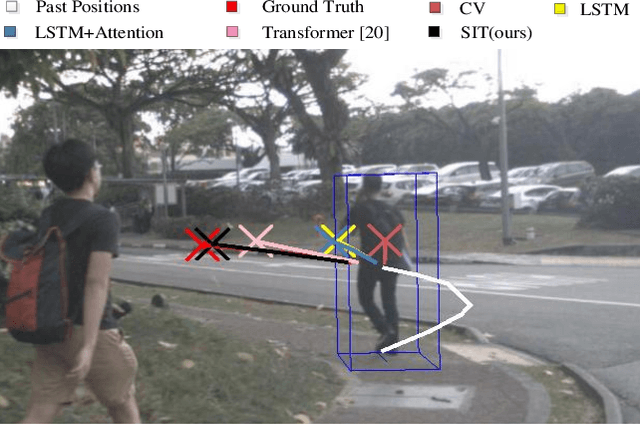
As a core technology of the autonomous driving system, pedestrian trajectory prediction can significantly enhance the function of active vehicle safety and reduce road traffic injuries. In traffic scenes, when encountering with oncoming people, pedestrians may make sudden turns or stop immediately, which often leads to complicated trajectories. To predict such unpredictable trajectories, we can gain insights into the interaction between pedestrians. In this paper, we present a novel generative method named Spatial Interaction Transformer (SIT), which learns the spatio-temporal correlation of pedestrian trajectories through attention mechanisms. Furthermore, we introduce the conditional variational autoencoder (CVAE) framework to model the future latent motion states of pedestrians. In particular, the experiments based on large-scale trafc dataset nuScenes [2] show that SIT has an outstanding performance than state-of-the-art (SOTA) methods. Experimental evaluation on the challenging ETH and UCY datasets conrms the robustness of our proposed model