 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reproducibility Study on Quantifying Language Similarity: The Impact of Missing Values in the URIEL Knowledge Base
May 17, 2024
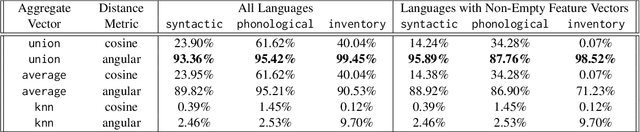


In the pursuit of supporting more languages around the world, tools that characterize properties of languages play a key role in expanding the existing multilingual NLP research. In this study, we focus on a widely used typological knowledge base, URIEL, which aggregates linguistic information into numeric vectors. Specifically, we delve into the soundness and reproducibility of the approach taken by URIEL in quantifying language similarity. Our analysis reveals URIEL's ambiguity in calculating language distances and in handling missing values. Moreover, we find that URIEL does not provide any information about typological features for 31\% of the languages it represents, undermining the reliabilility of the database, particularly on low-resource languages. Our literature review suggests URIEL and lang2vec are used in papers on diverse NLP tasks, which motivates us to rigorously verify the database as the effectiveness of these works depends on the reliability of the information the tool provides.