 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrate-Then-Delegate: Safety Monitoring with Risk and Budget Guarantees via Model Cascades
Apr 15, 2026Monitoring LLM safety at scale requires balancing cost and accuracy: a cheap latent-space probe can screen every input, but hard cases should be escalated to a more expensive expert. Existing cascades delegate based on probe uncertainty, but uncertainty is a poor proxy for delegation benefit, as it ignores whether the expert would actually correct the error. To address this problem, we introduce Calibrate-Then-Delegate (CTD), a model-cascade approach that provides probabilistic guarantees on the computation cost while enabling instance-level (streaming) decisions. CTD builds on a novel delegation value (DV) probe, a lightweight model operating on the same internal representations as the safety probe that directly predicts the benefit of escalation. To enforce budget constraints, CTD calibrates a threshold on the DV signal using held-out data via multiple hypothesis testing, yielding finite-sample guarantees on the delegation rate. Evaluated on four safety datasets, CTD consistently outperforms uncertainty-based delegation at every budget level, avoids harmful over-delegation, and adapts budget allocation to input difficulty without requiring group labels.
LTL Verification of Memoryful Neural Agents
Mar 04, 2025



We present a framework for verifying Memoryful Neural Multi-Agent Systems (MN-MAS) against full Linear Temporal Logic (LTL) specifications. In MN-MAS, agents interact with a non-deterministic, partially observable environment. Examples of MN-MAS include multi-agent systems based on feed-forward and recurrent neural networks or state-space models. Different from previous approaches, we support the verification of both bounded and unbounded LTL specifications. We leverage well-established bounded model checking techniques, including lasso search and invariant synthesis, to reduce the verification problem to that of constraint solving. To solve these constraints, we develop efficient methods based on bound propagation, mixed-integer linear programming, and adaptive splitting. We evaluate the effectiveness of our algorithms in single and multi-agent environments from the Gymnasium and PettingZoo libraries, verifying unbounded specifications for the first time and improving the verification time for bounded specifications by an order of magnitude compared to the SoA.
Verifiably Robust Conformal Prediction
May 29, 2024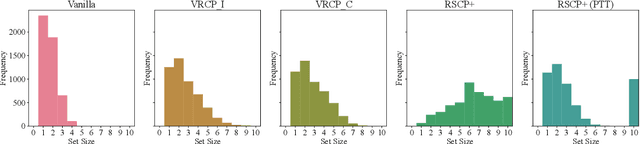



Conformal Prediction (CP) is a popular uncertainty quantification method that provides distribution-free, statistically valid prediction sets, assuming that training and test data are exchangeable. In such a case, CP's prediction sets are guaranteed to cover the (unknown) true test output with a user-specified probability. Nevertheless, this guarantee is violated when the data is subjected to adversarial attacks, which often result in a significant loss of coverage. Recently, several approaches have been put forward to recover CP guarantees in this setting. These approaches leverage variations of randomised smoothing to produce conservative sets which account for the effect of the adversarial perturbations. They are, however, limited in that they only support $\ell^2$-bounded perturbations and classification tasks. This paper introduces \emph{VRCP (Verifiably Robust Conformal Prediction)}, a new framework that leverages recent neural network verification methods to recover coverage guarantees under adversarial attacks. Our VRCP method is the first to support perturbations bounded by arbitrary norms including $\ell^1$, $\ell^2$, and $\ell^\infty$, as well as regression tasks. We evaluate and compare our approach on image classification tasks (CIFAR10, CIFAR100, and TinyImageNet) and regression tasks for deep reinforcement learning environments. In every case, VRCP achieves above nominal coverage and yields significantly more efficient and informative prediction regions than the SotA.
You Need to Pay Better Attention
Mar 03, 2024


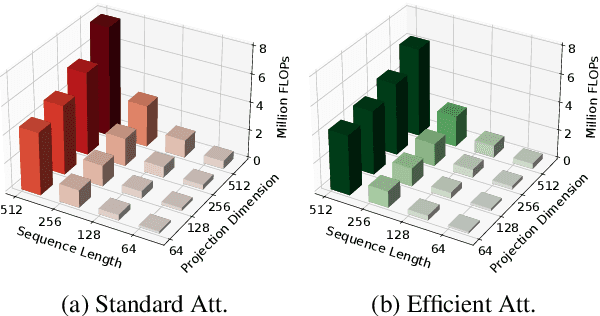
We introduce three new attention mechanisms that outperform standard multi-head attention in terms of efficiency and learning capabilities, thereby improving the performance and broader deployability of Transformer models. Our first contribution is Optimised Attention, which performs similarly to standard attention, but has 3/4 as many parameters and one matrix multiplication fewer per head. Next, we introduce Efficient Attention, which performs on par with standard attention with only 1/2 as many parameters as many parameters and two matrix multiplications fewer per head and is up to twice as fast as standard attention. Lastly, we introduce Super Attention, which surpasses standard attention by a significant margin in both vision and natural language processing tasks while having fewer parameters and matrix multiplications. In addition to providing rigorous mathematical comparisons, we evaluate the presented attention mechanisms on MNIST, CIFAR100, IMDB Movie Reviews, and Amazon Reviews datasets.
Tight Verification of Probabilistic Robustness in Bayesian Neural Networks
Jan 21, 2024We introduce two algorithms for computing tight guarantees on the probabilistic robustness of Bayesian Neural Networks (BNNs). Computing robustness guarantees for BNNs is a significantly more challenging task than verifying the robustness of standard Neural Networks (NNs) because it requires searching the parameters' space for safe weights. Moreover, tight and complete approaches for the verification of standard NNs, such as those based on Mixed-Integer Linear Programming (MILP), cannot be directly used for the verification of BNNs because of the polynomial terms resulting from the consecutive multiplication of variables encoding the weights. Our algorithms efficiently and effectively search the parameters' space for safe weights by using iterative expansion and the network's gradient and can be used with any verification algorithm of choice for BNNs. In addition to proving that our algorithms compute tighter bounds than the SoA, we also evaluate our algorithms against the SoA on standard benchmarks, such as MNIST and CIFAR10, showing that our algorithms compute bounds up to 40% tighter than the SoA.
Can We Generate Realistic Hands Only Using Convolution?
Jan 03, 2024
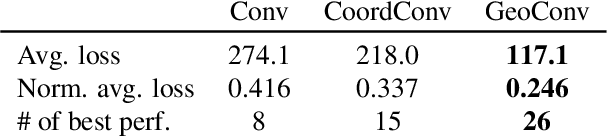
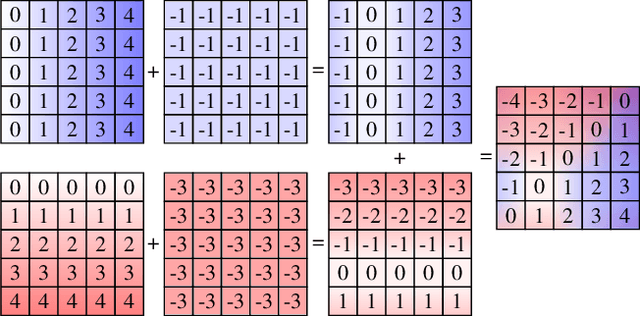
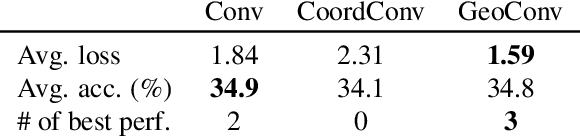
The enduring inability of image generative models to recreate intricate geometric features, such as those present in human hands and fingers has been an ongoing problem in image generation for nearly a decade. While strides have been made by increasing model sizes and diversifying training datasets, this issue remains prevalent across all models, from denoising diffusion models to Generative Adversarial Networks (GAN), pointing to a fundamental shortcoming in the underlying architectures. In this paper, we demonstrate how this problem can be mitigated by augmenting convolution layers geometric capabilities through providing them with a single input channel incorporating the relative $n$-dimensional Cartesian coordinate system. We show that this drastically improves quality of hand and face images generated by GANs and Variational AutoEncoders (VAE).
Lon-eå at SemEval-2023 Task 11: A Comparison of\\Activation Functions for Soft and Hard Label Prediction
Mar 04, 2023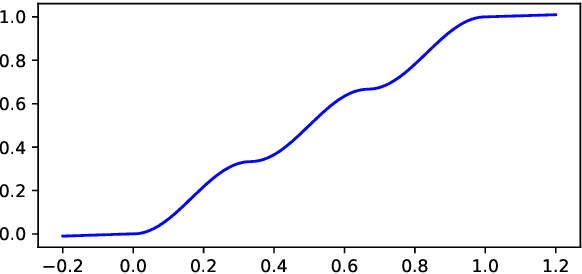



We study the influence of different activation functions in the output layer of deep neural network models for soft and hard label prediction in the learning with disagreement task. In this task, the goal is to quantify the amount of disagreement via predicting soft labels. To predict the soft labels, we use BERT-based preprocessors and encoders and vary the activation function used in the output layer, while keeping other parameters constant. The soft labels are then used for the hard label prediction. The activation functions considered are sigmoid as well as a step-function that is added to the model post-training and a sinusoidal activation function, which is introduced for the first time in this paper.