 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Need to Pay Better Attention
Paper and Code
Mar 03, 2024


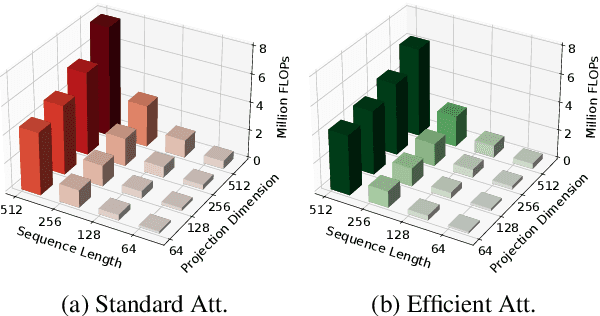
We introduce three new attention mechanisms that outperform standard multi-head attention in terms of efficiency and learning capabilities, thereby improving the performance and broader deployability of Transformer models. Our first contribution is Optimised Attention, which performs similarly to standard attention, but has 3/4 as many parameters and one matrix multiplication fewer per head. Next, we introduce Efficient Attention, which performs on par with standard attention with only 1/2 as many parameters as many parameters and two matrix multiplications fewer per head and is up to twice as fast as standard attention. Lastly, we introduce Super Attention, which surpasses standard attention by a significant margin in both vision and natural language processing tasks while having fewer parameters and matrix multiplications. In addition to providing rigorous mathematical comparisons, we evaluate the presented attention mechanisms on MNIST, CIFAR100, IMDB Movie Reviews, and Amazon Reviews datasets.