 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Trends in Linear Text Segmentation: a Survey
Nov 25, 2024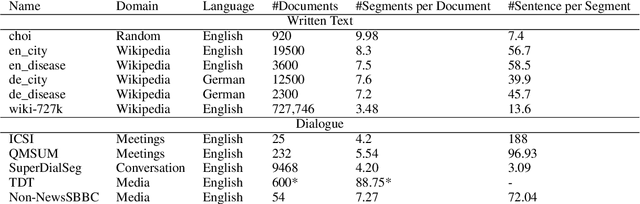
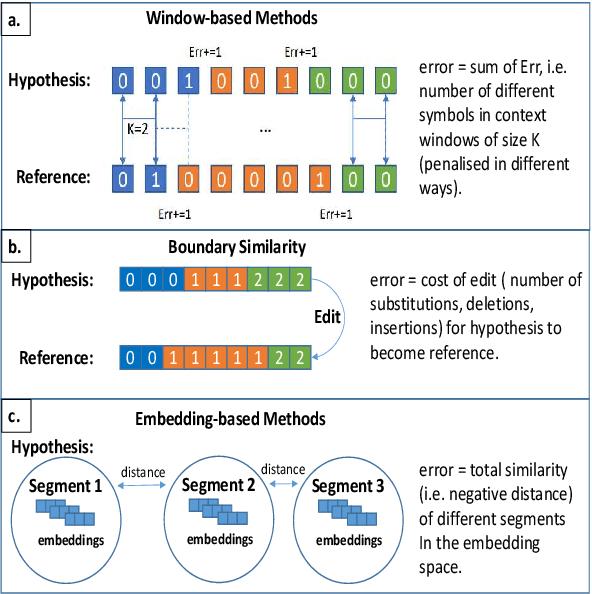
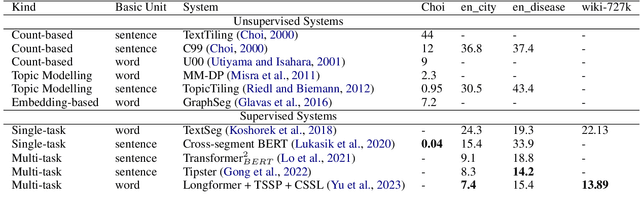
Linear Text Segmentation is the task of automatically tagging text documents with topic shifts, i.e. the places in the text where the topics change. A well-established area of research in Natural Language Processing, drawing from well-understood concepts in linguistic and computational linguistic research, the field has recently seen a lot of interest as a result of the surge of text, video, and audio available on the web, which in turn require ways of summarising and categorizing the mole of content for which linear text segmentation is a fundamental step. In this survey, we provide an extensive overview of current advances in linear text segmentation, describing the state of the art in terms of resources and approaches for the task. Finally, we highlight the limitations of available resources and of the task itself, while indicating ways forward based on the most recent literature and under-explored research directions.
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
The Semantic Scholar Open Data Platform
Jan 24, 2023



The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
Cosine Similarity of Multimodal Content Vectors for TV Programmes
Sep 23, 2020
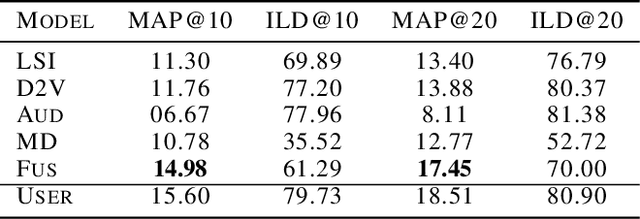
Multimodal information originates from a variety of sources: audiovisual files, textual descriptions, and metadata. We show how one can represent the content encoded by each individual source using vectors, how to combine the vectors via middle and late fusion techniques, and how to compute the semantic similarities between the contents. Our vectorial representations are built from spectral features and Bags of Audio Words, for audio, LSI topics and Doc2vec embeddings for subtitles, and the categorical features, for metadata. We implement our model on a dataset of BBC TV programmes and evaluate the fused representations to provide recommendations. The late fused similarity matrices significantly improve the precision and diversity of recommendations.