 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosine Similarity of Multimodal Content Vectors for TV Programmes
Sep 23, 2020
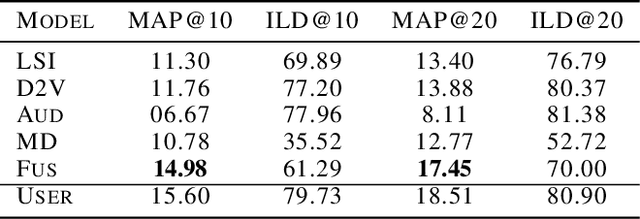
Multimodal information originates from a variety of sources: audiovisual files, textual descriptions, and metadata. We show how one can represent the content encoded by each individual source using vectors, how to combine the vectors via middle and late fusion techniques, and how to compute the semantic similarities between the contents. Our vectorial representations are built from spectral features and Bags of Audio Words, for audio, LSI topics and Doc2vec embeddings for subtitles, and the categorical features, for metadata. We implement our model on a dataset of BBC TV programmes and evaluate the fused representations to provide recommendations. The late fused similarity matrices significantly improve the precision and diversity of recommendations.