 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Content Moderation in the Fediverse
Jan 10, 2025



The Fediverse, a group of interconnected servers providing a variety of interoperable services (e.g. micro-blogging in Mastodon) has gained rapid popularity. This sudden growth, partly driven by Elon Musk's acquisition of Twitter, has created challenges for administrators though. This paper focuses on one particular challenge: content moderation, e.g. the need to remove spam or hate speech. While centralized platforms like Facebook and Twitter rely on automated tools for moderation, their dependence on massive labeled datasets and specialized infrastructure renders them impractical for decentralized, low-resource settings like the Fediverse. In this work, we design and evaluate FedMod, a collaborative content moderation system based on federated learning. Our system enables servers to exchange parameters of partially trained local content moderation models with similar servers, creating a federated model shared among collaborating servers. FedMod demonstrates robust performance on three different content moderation tasks: harmful content detection, bot content detection, and content warning assignment, achieving average per-server macro-F1 scores of 0.71, 0.73, and 0.58, respectively.
Urdu Word Segmentation using Conditional Random Fields (CRFs)
Jun 14, 2018
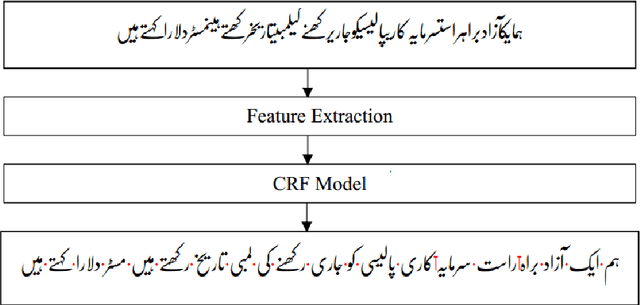


State-of-the-art Natural Language Processing algorithms rely heavily on efficient word segmentation. Urdu is amongst languages for which word segmentation is a complex task as it exhibits space omission as well as space insertion issues. This is partly due to the Arabic script which although cursive in nature, consists of characters that have inherent joining and non-joining attributes regardless of word boundary. This paper presents a word segmentation system for Urdu which uses a Conditional Random Field sequence modeler with orthographic, linguistic and morphological features. Our proposed model automatically learns to predict white space as word boundary as well as Zero Width Non-Joiner (ZWNJ) as sub-word boundary. Using a manually annotated corpus, our model achieves F1 score of 0.97 for word boundary identification and 0.85 for sub-word boundary identification tasks. We have made our code and corpus publicly available to make our results reproducible.
PronouncUR: An Urdu Pronunciation Lexicon Generator
Mar 05, 2018

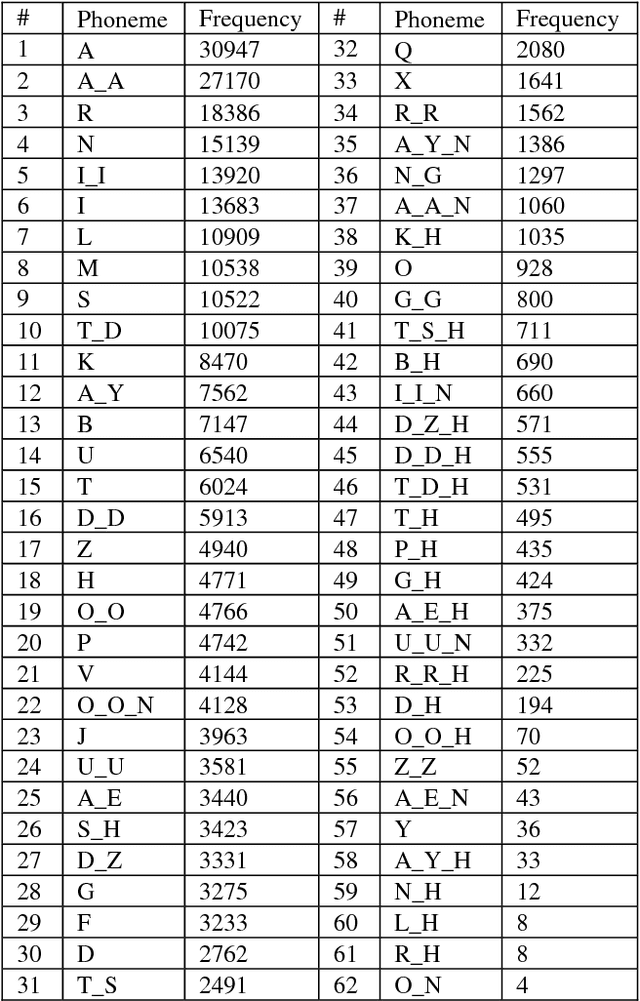
State-of-the-art speech recognition systems rely heavily on three basic components: an acoustic model, a pronunciation lexicon and a language model. To build these components, a researcher needs linguistic as well as technical expertise, which is a barrier in low-resource domains. Techniques to construct these three components without having expert domain knowledge are in great demand. Urdu, despite having millions of speakers all over the world, is a low-resource language in terms of standard publically available linguistic resources. In this paper, we present a grapheme-to-phoneme conversion tool for Urdu that generates a pronunciation lexicon in a form suitable for use with speech recognition systems from a list of Urdu words. The tool predicts the pronunciation of words using a LSTM-based model trained on a handcrafted expert lexicon of around 39,000 words and shows an accuracy of 64% upon internal evaluation. For external evaluation on a speech recognition task, we obtain a word error rate comparable to one achieved using a fully handcrafted expert lexicon.